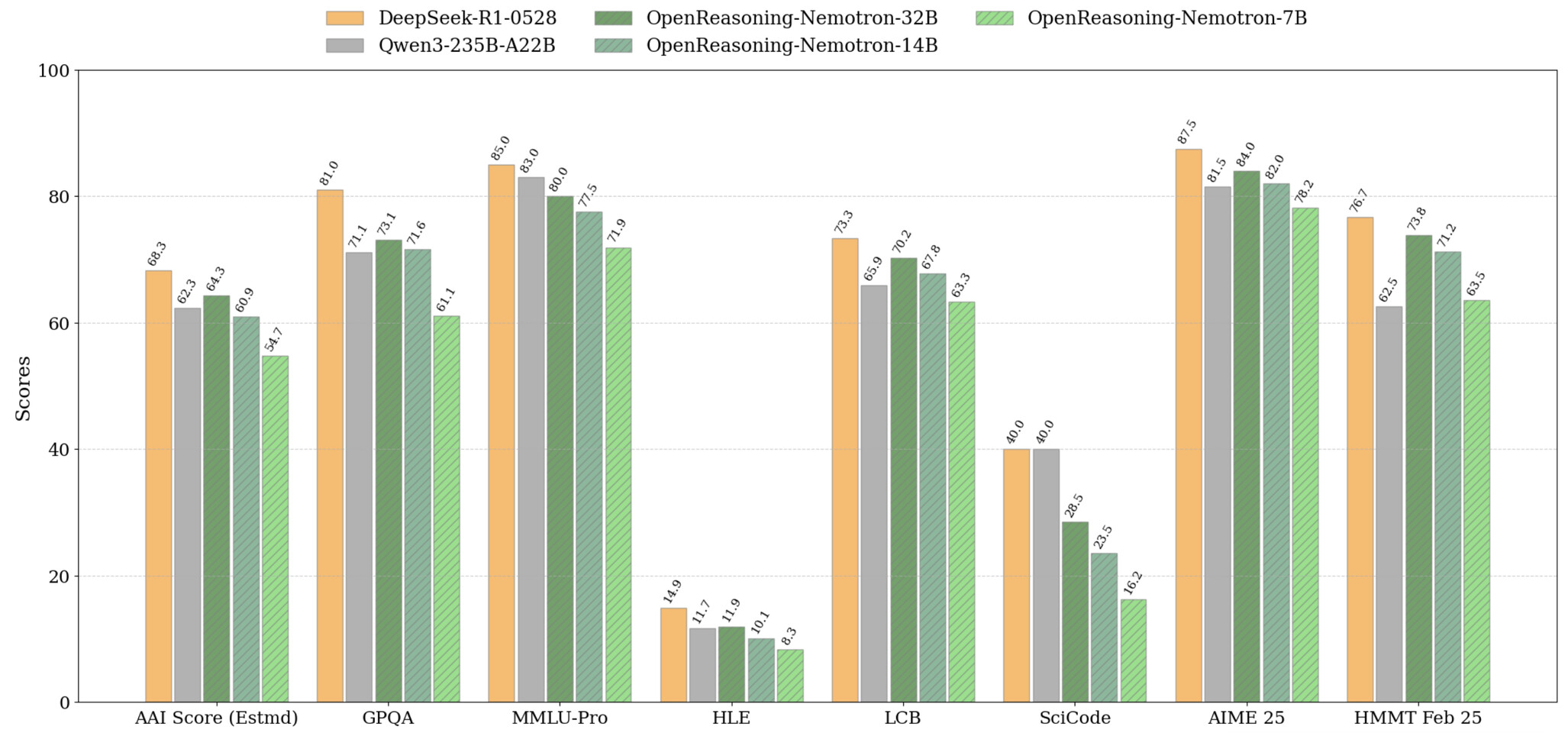
エヌビディア今日OpenReasoning-Nemotron をリリースしました。これは、15 億、70 億、140 億、320 億のパラメーターを備えた 4 つの合理化された推論モデルのコレクションであり、すべて 671 億のパラメーターを備えた DeepSeek R1 0528 から派生しています。大規模な「教師」モデルを 4 つの Qwen-2.5 ベースの「生徒」モデルに圧縮することで、NVIDIA は、高額な GPU 料金やクラウド使用量を気にすることなく、標準的なゲーム デバイスでも高度な推論実験を可能にします。

鍵となるのは高度な技術ではなく、生のデータです。 NVIDIA は、NeMo Skills パイプラインを使用して 500 万の数学、科学、コード ソリューションを生成し、純粋な教師あり学習を通じて各ソリューションを微調整しました。現在、320 億パラメータのモデルは、AIME24 で 89.2 ポイント、HMMT 2 月のコンテストで 73.8 ポイントを獲得していますが、15 億パラメータのバージョンでも 55.5 ポイントと 31.5 ポイントという堅実なスコアを達成しています。
NVIDIA は、これらのモデルを強力な研究ツールキットとして構想しています。 4 つのチェックポイントはすべて Hugging Face でダウンロードでき、強化学習駆動の推論を探索したり、特定のタスク向けにモデルをカスタマイズしたりするための強固な基盤を提供します。 GenSelect モード (質問ごとに複数回の反復) を使用すると、複数の並列ビルドを生成して最良の回答を選択することができ、その結果、複数の数学およびコーディング ベンチマークで OpenAI の o3-high パフォーマンスに匹敵する、またはそれを超える並外れた 32B モデル パフォーマンスが得られます。
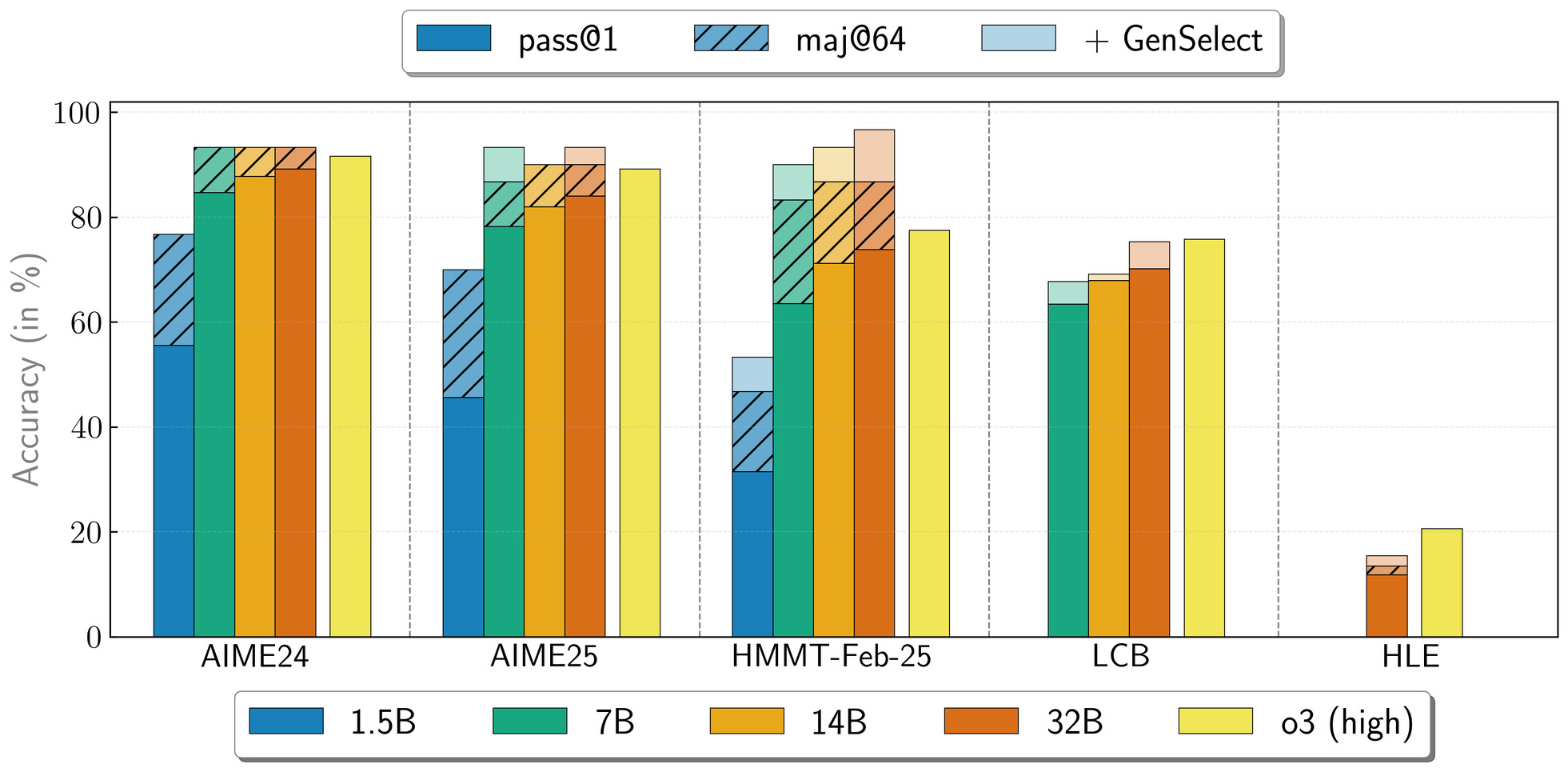
NVIDIA は強化学習ではなく教師あり微調整のみを使用してこれらのモデルをトレーニングしたため、コミュニティは将来の強化学習実験のための明確で高度な出発点を得ることができました。ゲーマーや家庭愛好家向けに、より強力なゲーム GPU をお持ちの場合は、最先端に非常に近づくことができる完全にローカライズされたモデルを入手できます。