今度は人間のソフトウェア工学が「逆」に行われた!ちょうど今、OpenAI の公式ブログで内部実験の 1 つが公開されました。3 人のエンジニアからなる初期チームが Codex エージェントを使用して、5 か月で「100 万行のコード製品」をゼロから作成しました。全プロセスにおいて、人間は手作業でコードを書くのではなく、「何をしたいのかを明確に考えてルールを確立する」ことに重点を置き、それ以外はすべてAIに任せます。
各ユーザーは毎日平均 3.5 件の PR (プル リクエスト、コード マージ リクエスト) をプッシュでき、PR 実行プロセス全体 (実装、テスト、ドキュメント、CI 構成) はエージェントによって処理されます。
OpenAI は、このワークフローに「ハーネス エンジニアリング」という非常に鮮やかな名前を付けました。

https://openai.com/index/harness-engineering/
この実験では、プログラマーは、夜遅くまでバグを書いて、夜遅くまでバグを修正する「コーダー」ではなくなり、本来の「実行者」が「ドライバー」になります。
これは、効率が 10 倍に向上する「生産性革命」であるだけでなく、「ソフトウェア エンジニアリング」の定義を覆すものであり、人類の「手動コーディング時代」の終わりを直接宣言するものです。
変化
空の Git リポジトリから開始します
この実験はAIの最初の提出から始まりました。
2025 年 8 月下旬、最初のコミットが空の倉庫に落ちたとき、それはもはや人間によって書かれたものではありませんでした。「アンカー」として機能できる既存の人間のコードはありませんでした。
さらに魔法的なのは、AI の動作方法をガイドするために使用された取扱説明書 AGENTS.md の最初のバージョンでさえ、AI 自身によって書かれたものです。
この倉庫は初日からエージェントによって形作られてきました。人間がコードを書くことは許されないが、これはこのプロジェクトにとって越えられない鉄則となっている。
これは怠惰のためではなく、一種の自虐的とも言える「意図的な練習」です。人間が「始める」ための逃げ道を遮断することによってのみ、チームは建築基準法という究極の問題を、誰にも頼らずに解決することを強いられるのです。
その結果、この 3 人という小さなチーム (後に 7 人に拡大) は、突然鞭を持った羊飼いのように見え、疲れ知らずのコーデックス エージェントのグループがコード草原を暴れ回るようになりました。
結果は驚くべきものです:5 か月、100 万行のコード。
エンジニアの役割を再定義する
この実験の初期の進捗は、OpenAI の研究者が予想していたよりも遅かった。
Codex が機能しないのではなく、環境が十分に明確に定義されていないのです。エージェントには、高レベルの目標を達成するために必要なツール、抽象化、内部構造が不足しています。
その結果、OpenAI エンジニアリング チームの主な仕事は 1 つになりました。エージェントに価値のある作業を完了できるようにします。
大きな目標を小さな構成要素 (設計、コード、レビュー、テストなど) に分割し、エージェントにこれらのブロックをまとめるように促し、それらを使用してより複雑なタスクのロックを解除します。
物事が失敗した場合、その答えが「もう一度試してみる」ということはほとんどありません。ここで前進する唯一の方法は、Codex に作業を任せることです。人間のエンジニアは通常、一歩下がって自問します。
どのような能力が欠けているのでしょうか?エージェントに表示され、強制できるようにするにはどうすればよいでしょうか?
プロセス全体を通じて、人間はほぼ完全にプロンプトの言葉を通じてシステムと対話します。エンジニアはタスクを説明し、エージェントを実行し、PR を開始させます。
PR を進めるために、研究者は Codex に変更をローカルで自己レビューさせ、追加のローカルおよびクラウド エージェントのレビューを要求し、人間またはエージェントのフィードバックに応答し、すべてのエージェントのレビュー担当者が満足するまでループで繰り返します。
時間が経つにつれて、ほとんどすべてのレビュー作業は「エージェント対エージェント」に移行しました。
アプリケーションの可読性の向上
コードのスループットが向上するにつれて、OpenAI は次のことを発見しました。AI コーディングのボトルネックは、手動による品質検査 (QA) の機能になります。
したがって、人間の時間と注意力は現実的な制約になります。
このボトルネックを打破するために、OpenAI のアプローチは、Codex がアプリケーションのユーザー インターフェイス、ログ、アプリケーション インジケーターなどを直接読み取ることができるようにすることです。
Chrome DevTools プロトコルをエージェント ランタイムに統合し、DOM スナップショット、スクリーンショット、ナビゲーションを処理するスキルを開発しました。
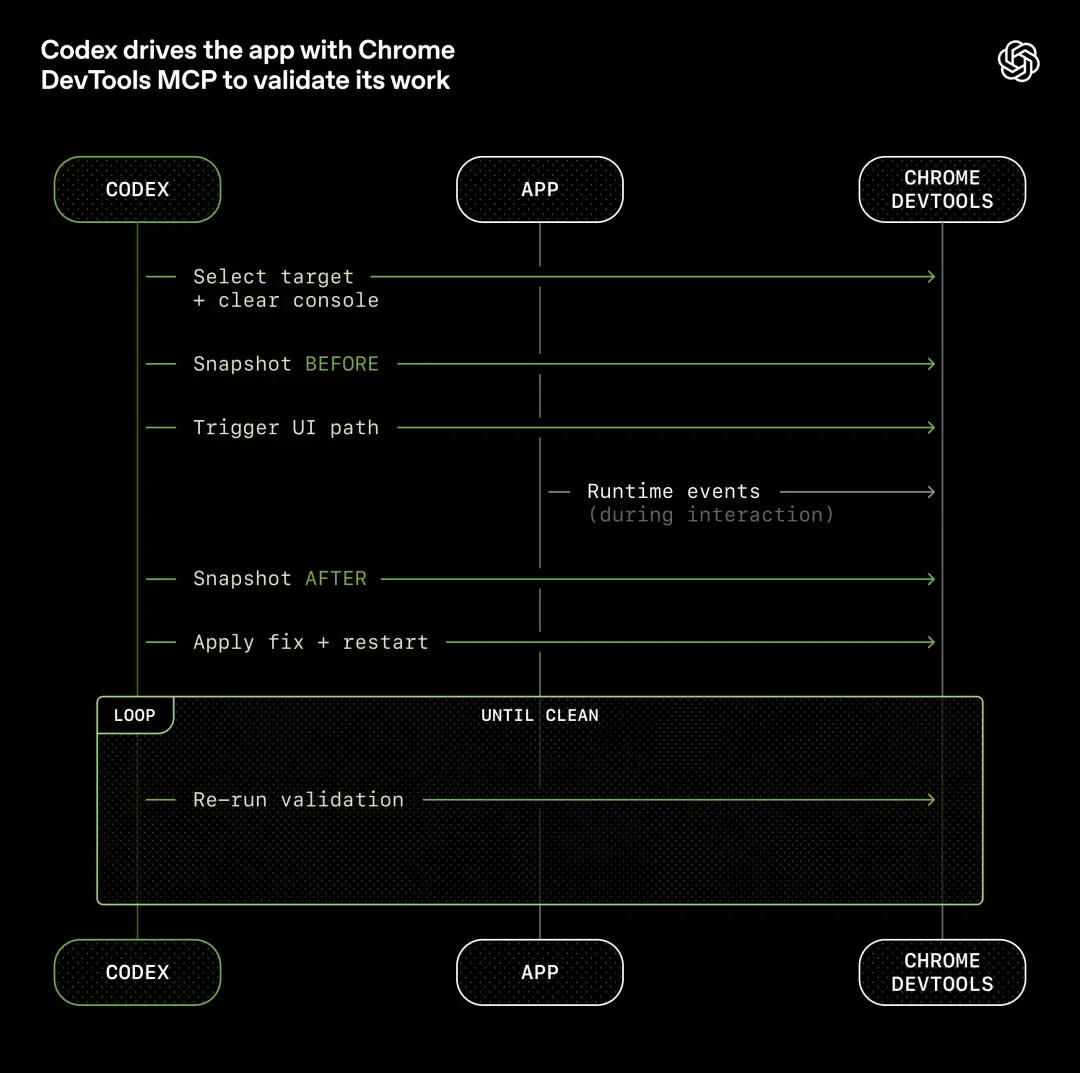
その結果、Codex はバグを再現し、修復を検証し、UI の動作について独自に推論することができます。
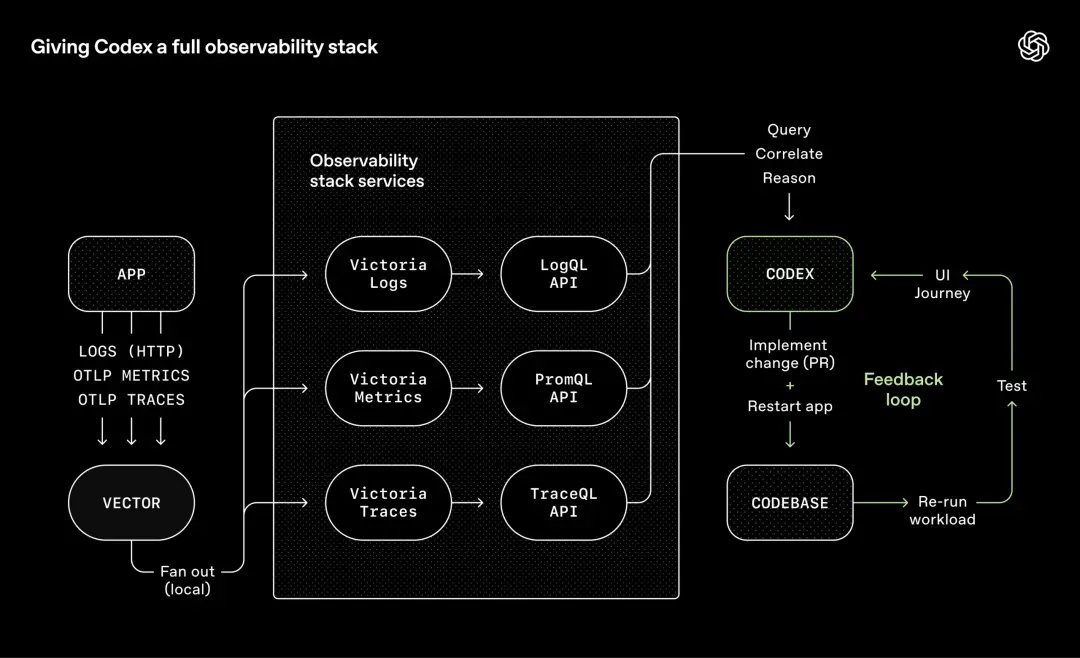
OpenAI は、可観測性ツールに対して同じアプローチを採用しています。
ログ、メトリック、およびトレースは、ローカルの可観測性スタックを通じて Codex に公開され、ワークツリー (ワークスペース) ごとに分離された一時的な環境になります。
タスクが完了すると、環境は破壊されます。
エージェントは LogQ を使用してログを確認し、PromQL を使用してインジケータを確認できます。
その結果、「サービスの起動が 800 ミリ秒以内に完了することを確認してください」または「4 つの主要なユーザー パス間のスパンが 2 秒を超えないようにしてください」などのプロンプトが実際に実行可能になります。
これを実行した後、OpenAI 研究者はよく次のことを目にします。Codex は、通常は人間が眠っている間に、一度に 6 時間以上継続的に動作します。
コーデックスに地図を与える
1,000ページのマニュアルよりも
コンテキスト管理は、エージェントに大規模で複雑なタスクを処理させる場合の最大の課題の 1 つです。
OpenAI 研究者が初期に学んだ簡単な教訓は次のとおりです。
Codex に 1,000 ページのマニュアルではなく地図を提供してください。
当初、チームは非常に大きな AGENTS.md ファイルを作成し、そのファイルにすべてのルール、ロジック、注意事項を詰め込もうとしました。それは大惨事となった。
なぜなら、AI の注意力も希少なリソースだからです。
1,000 ページの取扱説明書を与えると、細部がわからなくなったり、重要な制約を見逃したり、目標を間違えたりするでしょう。
さらに、このような単一の大きな文書を維持することは悪夢であり、すぐに「古いルールの墓場」になるでしょう。
その結果、チームはすぐに戦略を調整し、AGENTS.md を「宝の地図」に変えました。
このファイルの長さはわずか約 100 行で、具体的な知識は含まれておらず、倉庫の奥深くにあるより深い真実の情報源を示すナビゲーション マップのような目次だけが含まれています。
設計ドキュメントは、検証ステータスや「エージェントファースト」の動作原則を定義する一連の核となる信念を含めてカタログ化され、インデックス化されます。
実際の知識ベースは構造化された docs/ ディレクトリにあり、システムの信頼できる唯一の情報源です。
これは「漸進的開示」です。エージェントは最初から情報に圧倒されるのではなく、小さくて安定した入り口から始めて、次にどこを見るべきかを教えられます。
OpenAI の研究者も、これを強制するツールを持っています。
特殊な lint および CI タスクを通じて、ナレッジ ベースが最新で、相互リンクされており、正しい構造になっているかどうかを確認します。
アーキテクチャ文書は、ドメインの分割とパッケージの階層化のトップレベルのビューを提供します。品質ドキュメントでは、各製品領域とアーキテクチャ層にスコアが付けられ、ギャップが継続的に追跡されます。
AIが古い情報を読み取らないようにするために、チームは特別に「ドキュメントガーデナー」エージェントを配置しました。
ジョブは 1 つだけです。ドキュメントを定期的にスキャンし、コード実装と矛盾する古い記述を見つけて、修正 PR を自動的に開始します。
インテリジェントエージェントに「理解」させましょう
ウェアハウスは完全にエージェントによって生成されるため、OpenAI 研究者の目標の 1 つは、エージェントがウェアハウス自体に依存するだけで完全なビジネス ドメインを理解できるようにすることです。
エージェントの観点から見ると、実行時コンテキストでアクセスできない知識は存在しません。
たとえば、Google ドキュメントに置かれた知識、チャット記録、人間の脳などはすべてシステムからは見えません。
表示できるのは、コード、マークダウン、スキーマ、実行可能プランなど、ウェアハウス内のバージョン管理された成果物だけです。
エージェントがこの状況に応じた知識を見つけられない場合、彼らは仕事上の新しい同僚と同じように無知になり、ビジネスで実際に何が起こっているのか全く分かりません。
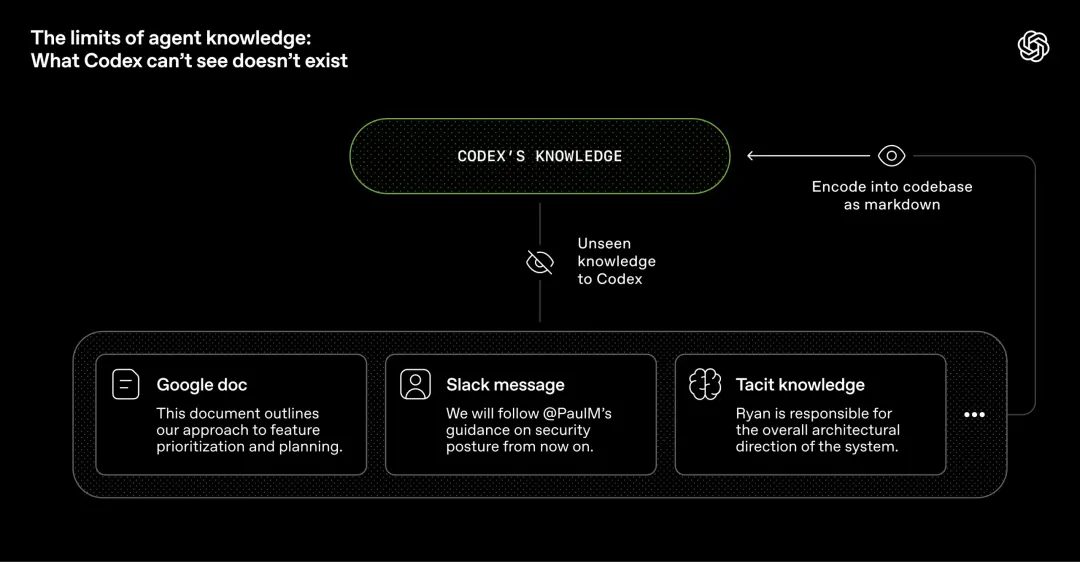
したがって、ますます多くのコンテキストを倉庫に押し戻す必要があります。
もちろん、Codex により多くのコンテキストを与えるということは、より分散した指示を与えるということではなく、情報を整理して構造化し、推論できるようにすることを意味します。
自動柵
プログラマーがコードの世界の「羊飼い」になれるようにしましょう
エージェントが完全に生成したコード ベースの一貫性を保つには、ドキュメントだけでは十分ではありません。
結局のところ、AI は確率モデルです。幻覚が見られたり、怠惰になったり、「実行しているように見えても、実際には混乱している」コードを作成したりすることがあります。
どうやって解決すればいいでしょうか?
エージェントは、境界が明確で構造が予測可能な環境で最も効果的に機能します。
OpenAI では、実装の詳細を細かく管理するのではなく、「不変条件」を強制することで、エージェントが基盤を壊すことなく高速で作業を進めることができます。
これは、毎日何千マイルも移動するコーデックスのような AI 馬に手綱と鞍を付けるようなものです。
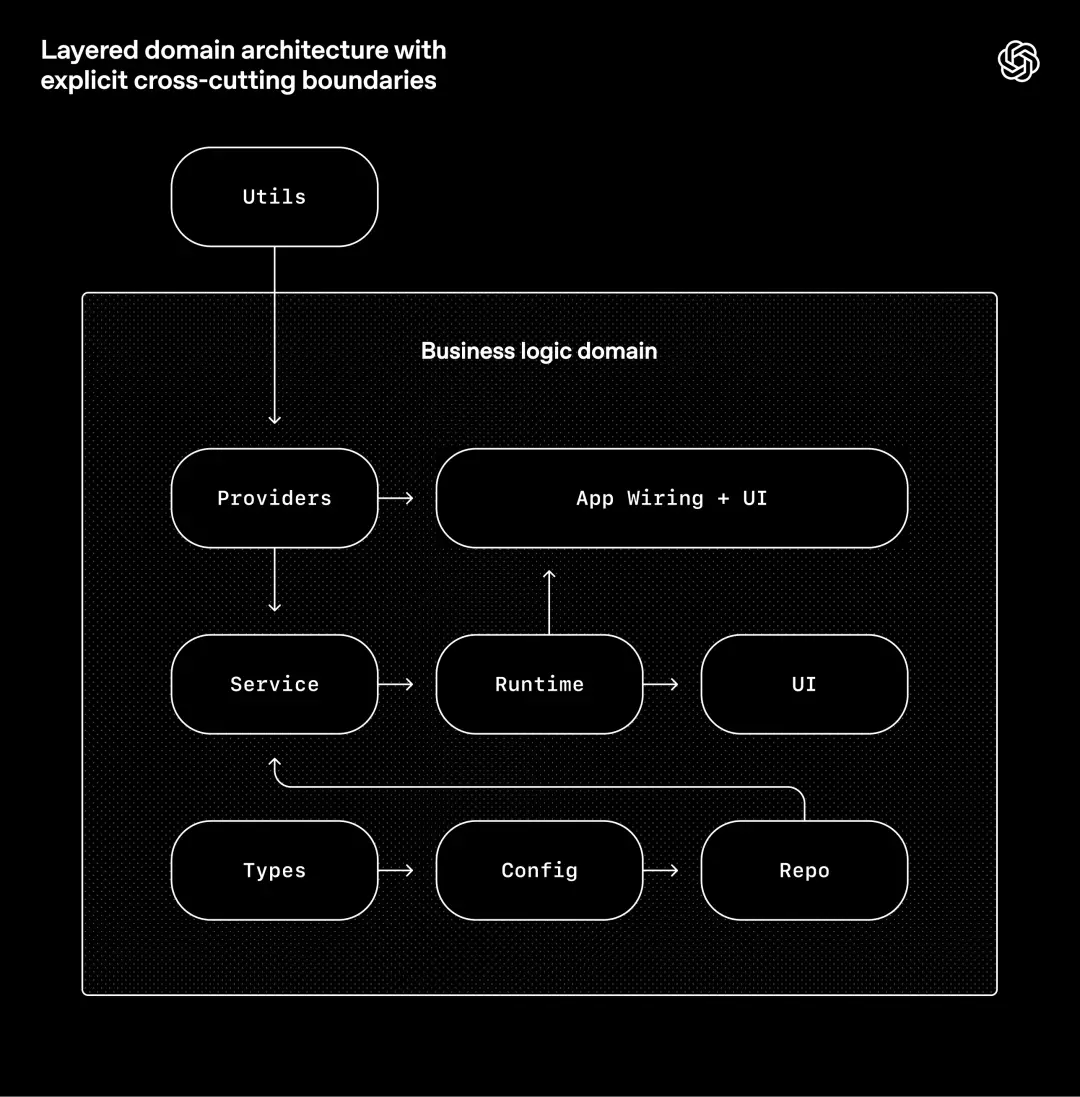
OpenAI は、厳密なアーキテクチャ モデルに基づいてシステムを構築します。各ビジネス領域には固定の階層があり、依存関係の方向性が厳密に検証され、限られた法的境界のみが許可されます。
ルールは単純です。各ビジネス領域 (アプリ設定など) 内では、コードは固定階層に沿った "forward" にのみ依存できます。
タイプ→構成→リポジトリ→サービス→ランタイム→UI
横断的な関心事 (認証、コネクタ、テレメトリ、機能スイッチなど) は、1 つの明示的なインターフェイス (プロバイダー) を通じてのみ利用できます。
その他の依存関係は禁止されており、カスタム lint (これも Codex によって生成される) および構造テストを通じて強制されます。
この種のアーキテクチャは通常、企業規模が数百人に達する場合にのみ慎重に設計されます。ただし、コーディング エージェントの場合、これは前提条件です。
さらに、OpenAI 研究者は、次のような一連の「味の不変条件」を定義しました。
構造化ログを強制する
スキーマと型の命名規則
最大ファイルサイズ
プラットフォームレベルの信頼性要件
このプロセスでは、厳格さが求められる部分と権限を委譲できる部分を明確に区別する必要があります。
これは、大規模なエンジニアリング プラットフォームの管理に似ています。国境での集中管理と高度な内部自律性です。
AI によって生成されたコードは人間の美学に準拠していない可能性がありますが、それが正しく、保守可能で、インテリジェント エージェントによって読み取れる限りは問題ありません。
このプロセスにおいて、人間の嗜好は消えることはなく、システムに「エンコード」され続けます。
レビュー コメント、リファクタリング PR、およびユーザーのバグはドキュメントの更新に変換されるか、ツール ルールに直接アップグレードされます。
ドキュメントだけでは不十分な場合は、ルールをコードに書き込む必要があります。
キーボードを捨てる
勇気を出してAIをコントロールしよう
OpenAI によるこの実験では、次のことが発表されました。多数の CRUD ベースの仕事が再構築されています。
ゼロから始めたシステムを 3 人で (コードを 1 行も書かずに) 5 か月以内に 100 万行規模まで構築できるとしたら、従来のソフトウェア会社の巨大な開発チームは依然として存在する必要があるでしょうか?
これからの新しい時代、エンジニアの定義は大きく書き換えられます。
必要なのは、システムの境界を定義し、モジュール間の制約を設計し、AI が迷わないようにする「フェンス」を構築できる強力な「アーキテクチャ能力」です。
同時に、正確な「表現スキル」も必要であり、AI に対して自分の意図を最も明確な言語 (自然言語でも構造化文書でも) で説明する方法を学びます。
AIプログラミングを拒否し、手作業でコーディングすることにこだわる人は、やがてその波に飲み込まれることになる。 AI を制御する方法を知っているプログラマーだけが、AI 時代の勝者になる可能性があります。