GPT-5.6が登場しましたが…何のモデルでしょうか?今回の OpenAI は、これまでよく知られていた Pro、Mini、Instant という名前を使用しませんでした。その代わりに、一度に 3 つの名前が思いつきました。GPT-5.6 ソル、GPT-5.6 テラ、GPT-5.6 ルナ。ソルは太陽、テラは地球、ルナは月です。
新しいモデルの宇宙のように派手に聞こえます。しかし実際には、これは私たちがよく知っている製品の階層化です。つまり、最強のフラッグシップ モデル、日常使用向けのバランスの取れたモデル、そして安くて高速で大規模な通話に適した軽量モデルです。
OpenAIからの公式声明は次のとおりです。GPT-5.6 シリーズは今後数週間以内に完全に公開される予定ですが、現在は米国政府の要請により、コーデックスと API の「信頼できるパートナー」の少数のグループに限定的にプレビューされています。
まずは公開されている情報を見てみましょう。

最上級グレードはGPT5.5と同価格
OpenAI は今回、GPT-5.6 に Sol、Terra、Luna の 3 つのレベルを割り当てました。
公式発表によると、Solはフラッグシップモデル、Terraは日常業務向けのバランスの取れたモデル、Lunaは高速、安価、軽量のモデルだという。
3 レベルのモデルは一度にリリースされ、基本的には大規模モデル製品で最も一般的な 3 層構造に対応しています。つまり、最も強力なモデルが機能の上限を担当し、中間モデルがほとんどの日常タスクを担当し、軽量モデルが速度、コスト、および高同時呼び出しを担当します。
3つのレベルは価格からもわかります。
OpenAIが発表したAPI価格によると、GPT-5.6 は 100 万トークンごとに課金されます。Sol は入力に 5 米ドル、出力に 30 米ドルかかります。 Terra の料金は入力に 2.5 米ドル、出力に 15 米ドルです。 Luna のコストは入力に 1 米ドル、出力に 6 米ドルです。
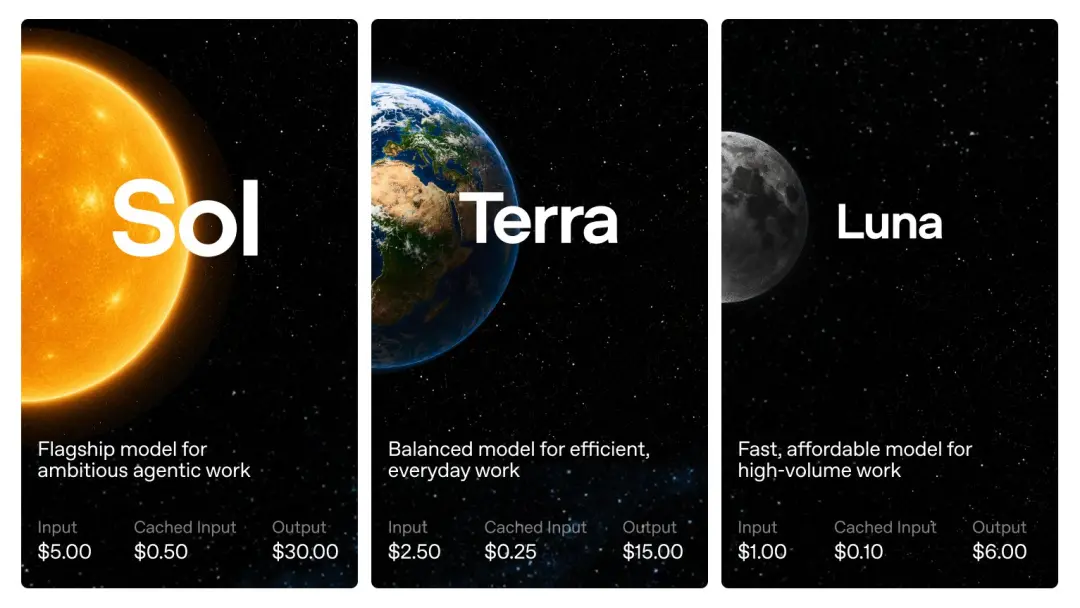
お気づきかと思いますが、GPT-5.6 Sol は新世代のフラッグシップ モデルですが、価格は GPT-5.5 Pro ではなく GPT-5.5 標準バージョンと一致しています。
Terra は GPT-5.5 の半分まで直接低下しましたが、Luna は GPT-5.5 のわずか 5 分の 1 でした。
GPT-5.5 Pro は、現時点でも OpenAI の最も高価なモデルです。価格は、インプットの場合は 30 米ドル/100 万トークン、アウトプットの場合は 180 米ドル/100 万トークンです。価格はGPT-5.5標準版、GPT-5.6 Solの6倍です。将来的に「プロフェッショナルなタスクにより適した」別の GPT-5.6 ユニバースが登場するかどうかはわかりません (冗談です)。
SolはこのGPT-5.6シリーズの最上位モデルであり、正式発表でも最も多くの時間を費やして紹介されているモデルでもあります。
OpenAI は、コーディング、生物学的研究、ネットワーク セキュリティの機能に焦点を当て、GPT-5.6 Sol を現時点で最強のモデルと呼んでいます。
一言で言えば、Solは「最高級モデル」という位置づけです。これは通常のチャット シナリオではなく、より複雑で実際の作業に近いタスクに対応します。
たとえば、コード シナリオでは、目標に向かって進み続けることができます。まず問題を理解し、次にステップを分割し、次にツールを呼び出し、コマンドを実行し、結果を確認し、タスクが完了するまでエラーが発生した場合は修正します。
より困難なタスクの処理において Sol をサポートするために、OpenAI は 2 つの新しいメカニズムを GPT-5.6 に導入しました。
最初のものはと呼ばれます最大の推論努力, これは「最大の推論力」と訳せます。
一般的な理解は、ソルが問題について明確に考える時間が増え、深い推論を行うのに時間がかかることを意味します。最初の反応では解決できない複雑なタスクに適しています。
2 番目のものはと呼ばれますウルトラモード、それは「スーパーモード」として理解できます。
このモデルの焦点は、複数のサブエージェントが複雑なタスクに一緒に参加できるようにすることです。これまではAIアシスタントが単独で作業していましたが、現在は「AIマネージャー」が複数のアシスタントを率いて個別に問題に対応することで、複雑な業務の進行を加速させていると捉えることができます。
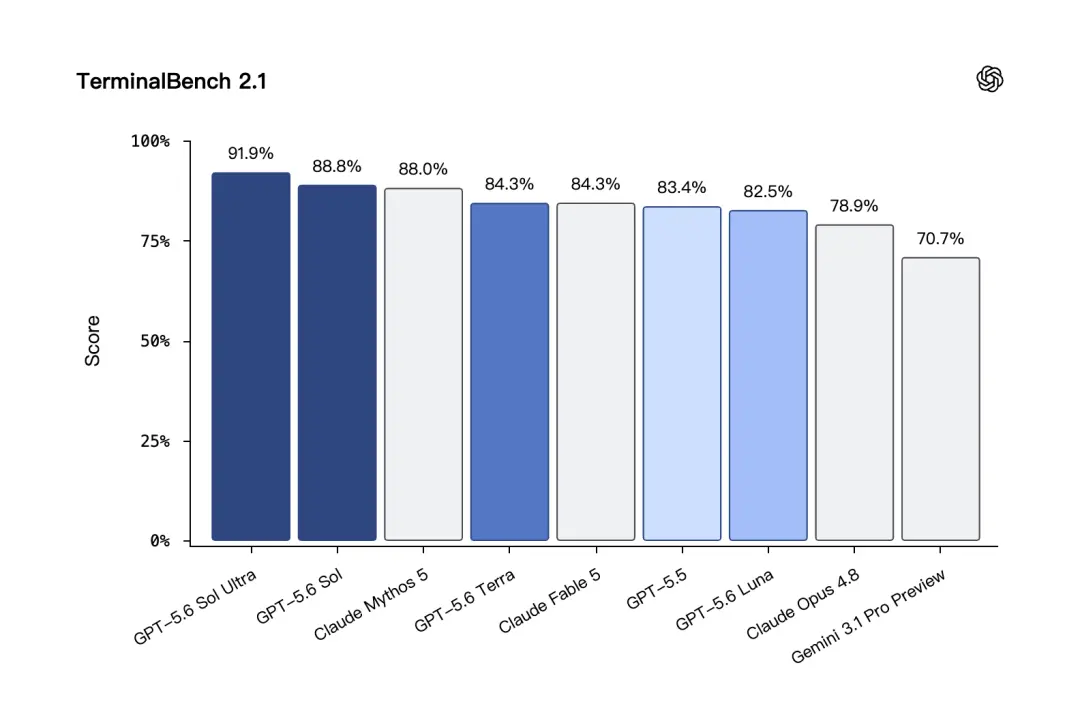
Terminal-Bench 2.1 は、実際の開発プロセスに近いテストです。コマンド ライン環境でモデルが問題を段階的に解決できるかどうかをテストします。 GPT-5.6 Solはこのテストで88.8%という高スコアを達成し、ウルトラモードではさらに高いスコアを達成しました。
OpenAI は、モデルがより広くオープンになれば、より完全な評価結果セットがリリースされるだろうと特に述べました。
テラはミドルレンジです。
OpenAI の Terra の紹介はそれほど長くありませんが、その位置づけは明確です。それは日常業務のためのバランスのとれたモデルです。
つまり、必ずしも最強を追求するのではなく、効果、スピード、コストのバランスを考えたものです。関係者は、Terraの機能はGPT-5.5に近いが、価格は半額であると強調した。
OpenAI のビジョンでは、Terra は GPT-5.6 シリーズの中で最も一般的に使用されるものになる可能性があります。通常のオフィス タスクでは、Sol のような最高の機能は必要ありませんが、安定していて、安価で、使いやすい必要があります。
Terminal-Bench 2.1 テストでは、GPT-5.6 Terra は 84.3% を獲得し、これは Claude Fable 5 と同じです。
Luna则是最低成本档。
OpenAI の Luna の位置付けも非常にシンプルです。高速かつ安価で、大規模で高頻度でコスト重視のタスクに適しています。
たとえば、バッチ要約、テキスト分類、情報抽出、簡単な質疑応答などです。これらのタスク自体は必ずしも複雑ではありませんが、通話量が非常に多くなる場合があります。 Luna の役割は、これらの軽量タスクを低コストで実行することです。
これら 3 つのモデルのうち、Sol は最高の機能を担当し、Terra は日常の作業を担当し、Luna は速度とコストを担当します。派手に聞こえますが、OpenAI は、大規模なモデル業界のすでに成熟したレイヤーを再パッケージ化しているだけです。
でも、安くて使いやすければ名前は重要ではないと思います。

価格に見合った価値
公式発表を見る限り、今回GPT-5.6 Solで公開されたベンチマークはそれほど多くありません。 OpenAI自身は、現時点ではモデルの性能を事前に外部に知らせるだけなので、まずは一連の評価結果を共有するとしている。
しかし、リリースされた一連のベンチマークには明確な方向性があり、コード、生物学、ネットワーク セキュリティの 3 つの領域に焦点を当てています。
前述の Terminal-Bench 2.1 はコード方向に属します。これは、モデルがコマンド ライン環境での実際の開発プロセス (計画、繰り返しの変更、ツールの呼び出し、結果の検証など) を完了できるかどうかをテストします。
コードに加えて、OpenAI は生物学的ベンチマークである GeneBench v1 も強調しました。
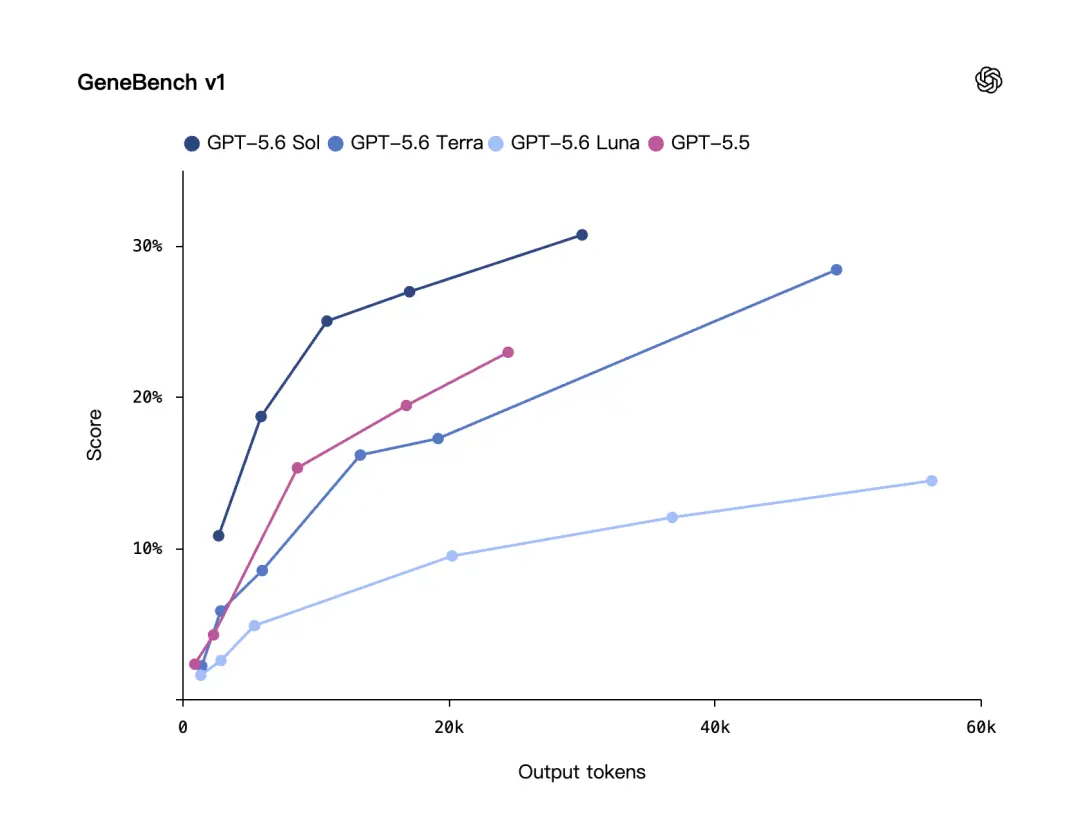
GeneBench v1 は、モデルが実際の科学研究プロセスにより近い分析問題を処理できるかどうかに焦点を当て、長期的なゲノミクスおよび定量的生物学的分析タスクを評価します。
OpenAI によると、GPT-5.6 Sol は GeneBench v1 上で GPT-5.5 よりも優れたパフォーマンスを発揮します。使用するトークンを減らす。
3 番目の重要な方向性はネットワーク セキュリティです。 OpenAI は、GPT-5.6 Sol が、特に長期的なセキュリティ タスク (脆弱性調査や脆弱性悪用関連タスクを含む) にとって、現時点で最も強力なネットワーク セキュリティ モデルであると主張しています。
ここには ExploitBench と呼ばれるベンチマークがあります。これは一般的なセキュリティの質問と回答ではなく、脆弱性悪用シナリオに近い評価です。
OpenAI は ExploitBench について次のように述べています。GPT-5.6 Sol のパフォーマンスは Mythos Preview と同等ですが、出力トークンの約 3 分の 1 しか使用しません。
とはいえ、公式写真にはまだギャップがあります。
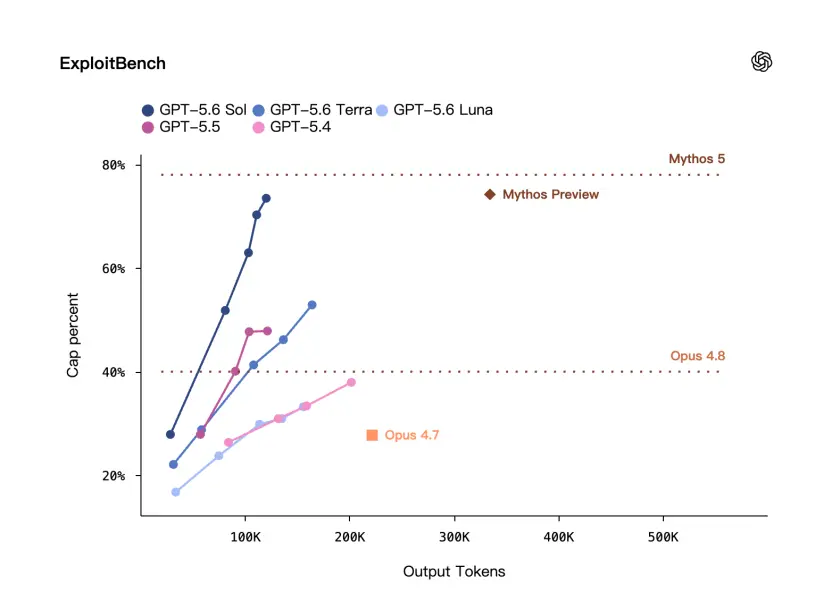
今回、OpenAI が繰り返し強調したことがわかります。彼らは非常に有能であると同時に、非常に効率的でもあります。
出力トークンが少ないということは、モデルがより簡潔になり、同様のタスクを完了する際の回り道が少なくなることを意味します。また、実際の通話コストがより制御可能であることも意味します。
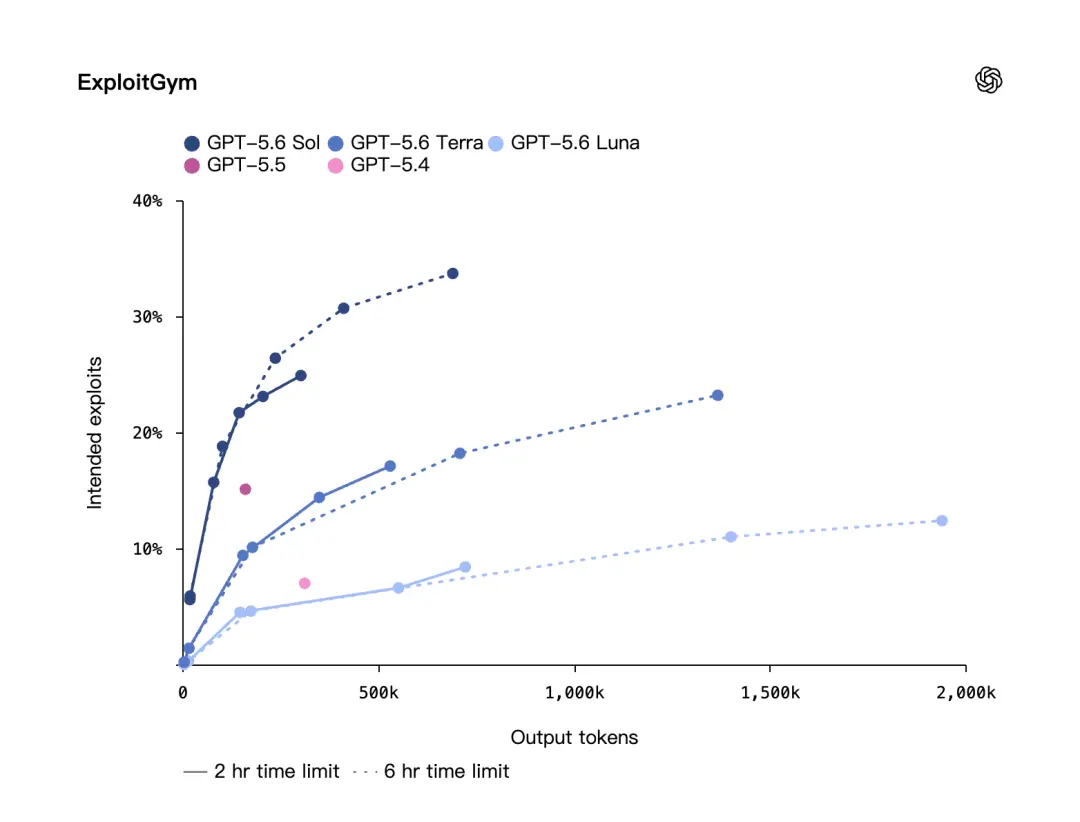
OpenAI は、別のサイバーセキュリティ ベンチマークである ExploitGym についても言及しました。
このベンチマークは、カリフォルニア大学バークレー校の研究者が OpenAI およびその他の最先端の研究所と協力して作成したものです。 OpenAIによると、ExploitGymではGPT-5.6のSol、Terra、Lunaモデルはいずれもネットワークセキュリティ機能の大幅な向上を示しており、推論強度が高まるにつれてパフォーマンスも強化されるという。
これは、GPT-5.6 の改良はモデル本体の強化だけでなく、推論方法も強化されたことを意味します。モデルに考える時間をもっと与え、より長い推論の連鎖を実行させると、結果はより良くなります。

限定プレビューについて
Sol、Terra、Luna が GPT-5.6 の表面的な変更であるとすれば、より注目すべきは、今回 OpenAI が完全にオープン化されていないことです。
公式発表によると、現時点では GPT-5.6 は、Codex および API での限定的なプレビューとして、少数の「信頼できるパートナー」グループに対してのみ利用可能です。
さらに、この限定的なプレビューは「米国政府の要請に応じて」実施され、プレビューに参加するパートナーのリストは米国政府と共有されています。
最近、米国政府は最先端の AI モデル、特により強力なコード、ネットワーク セキュリティ、エージェント機能を備えたモデルへの関与を大幅に強化しています。
今年6月、米国政府はAIサイバーセキュリティに関連する新たな大統領令を発行し、最先端のモデル開発者がモデルがより広くリリースされる前に連絡して評価できるようにする自主的な枠組みを確立することを提案した。
この行政命令の法曹界の解釈は、名ばかりの強制実施権でも正式な承認制度でもないが、モデルの放出前評価に政府が参加する制度的枠組みを設けたものである。
「最初は小規模でプレビューし、リストを政府と共有する」という GPT-5.6 Sol のリリース モデルは、最先端モデルのリリース プロセスに対する政府介入の最初の明確な痕跡と見ることができます。
OpenAI自身も発表の中で、このアプローチを取る理由は将来のモデルリリースをサポートするために政府と反復可能なプロセスを模索するためであると説明している。
政府介入の主な理由はネットワーク セキュリティです。
公式発表では、ネットワーク セキュリティが多くのスペースを占めています。OpenAI は、GPT-5.6 Sol が現時点で最も強力なネットワーク セキュリティ モデルであり、脆弱性調査、脆弱性分析、セキュリティ防御などの長期的なタスクに強力な支援を提供できると強調しています。一方で、自身のサイバークリティカルしきい値を超えていないことを説明するのに多くのスペースを費やしています。
OpenAI の準備フレームワークでは、高リスクの機能がさまざまなレベルに分割されています。高に達すると、モデルが既存の深刻なリスクを増幅する可能性があることを意味します。クリティカルに達するということは、モデルが新たな前例のない深刻なリスクを引き起こす可能性があることを意味します。
OpenAIは、GPT-5.6 Solはサイバークリティカルに達していないことを繰り返し強調してきました。実際、このモデルは政府、顧客、一般大衆に次のように伝えています。このモデルは、特にネットワーク セキュリティ タスクにおいては非常に強力ですが、最も危険なネットワーク攻撃チェーンを単独で完了するには十分強力ではありません。
ネットワーク セキュリティ機能は両刃の剣のようなものです。強力であればあるほど、防御側が脆弱性を発見し、パッチを作成し、セキュリティ テストを実施するのに役立ちます。しかし、彼らが非常に強力であるからこそ、政府はその乱用についても懸念することになる。
OpenAIは、このリリースには政府とのプロセスを検討する必要があることを認めたが、この政府によるアクセスプロセスが長期的なデフォルトのメカニズムになるべきではないと考えていることも公式発表の中で明らかにした。
理論的根拠: 最も強力なツールの入手が遅れると、世界中のユーザー、開発者、企業、ネットワーク防御者、パートナーが最良のツールを入手するのが遅れることになります。
ある意味、最先端モデルは新たなリリースフェーズに突入している。
大規模モデルの機能がコード、生物学、ネットワーク セキュリティ、エージェント実行などの領域に集中すると、現実世界のセキュリティに影響を与える可能性のあるテクノロジとみなされ始めます。
テクノロジーがこのように見られると、出版権を完全に企業自体の手に残すことは困難になります。