ウォール・ストリート・ジャーナルによると、AIの分野は大きな変化を迎えており、大小のテクノロジー企業に大きな影響を与えるだろう。過去 5 年間、AI 分野の主な焦点は大規模な言語モデルのトレーニングでした。これは、数万個のチップを必要とし、大量のエネルギーを消費し、遠隔地にある大規模なデータセンターで行われる高価なプロセスです。このトレーニング プロセスでは、何千もの特殊なマイクロプロセッサ チップのクラスターを使用して、数十億の情報 (単語の定義、歴史的事実、財務統計、猫の写真など) をモデルにフィードする必要があります。チップ クラスターは、1 日 24 時間、年中無休で、数週間、場合によっては数か月間稼働します。

図 1: Huang Renxun は推論チップに焦点を当て始めます
トレーニングから推論まで
現在、より多くの企業が AI エージェントを導入し、大規模な言語モデルに基づいて構築された新しいツールを商品化しようとしているため、焦点は推論、つまりトレーニングされた AI モデルがユーザーのクエリに応答できるようにするコンピューティングの種類に移ってきています。
調査会社 Gartner のデータによると、世界の推論インフラストラクチャ (チップ、データセンター、ネットワーク ハードウェアを含む) への設備投資は、今年初めてトレーニング設備への設備投資を超えると予想されています。 2029 年までに、企業は推論に 720 億ドルを費やし、これはトレーニングに費やされる 370 億ドルのほぼ 2 倍になります。
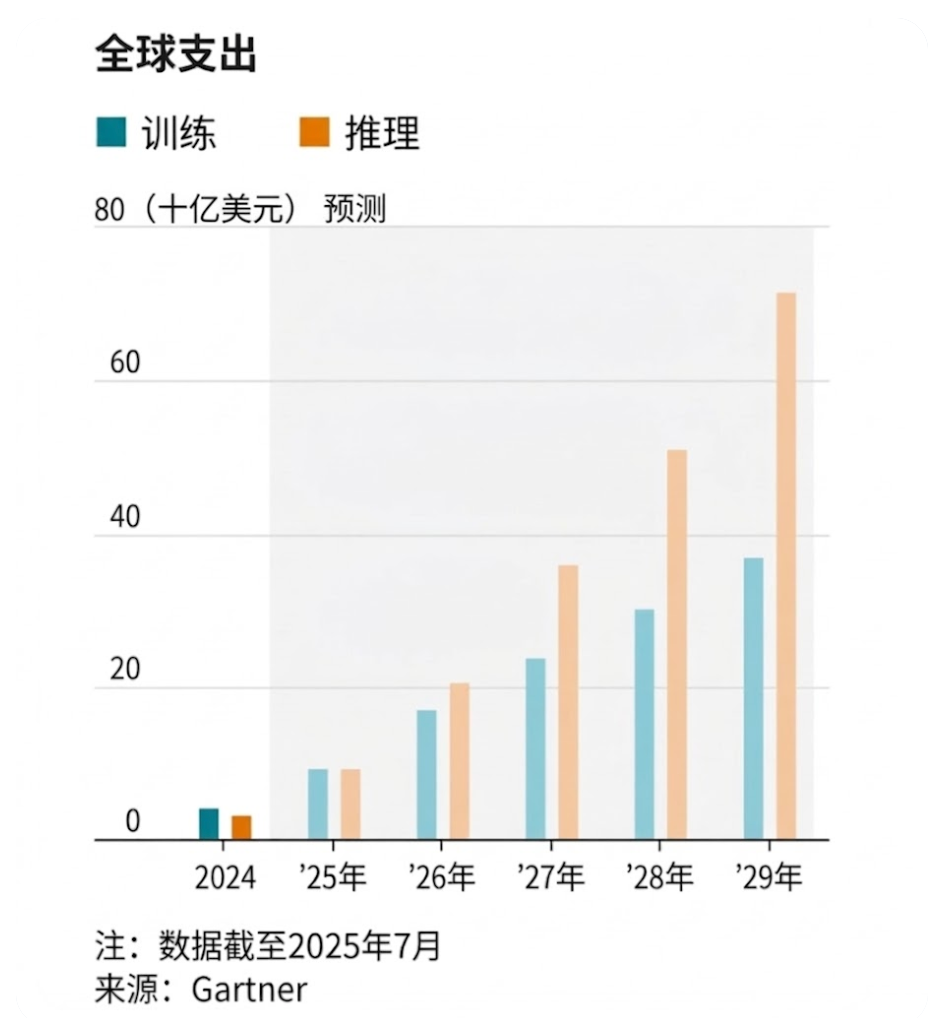
推論への支出がトレーニングを超える
この変化は、テクノロジー企業が購入するチップの種類が大きく変わることを意味する。 Nvidia は、モデルのトレーニングに必要な生の処理能力を提供する GPU と呼ばれるチップを販売することで、世界で最も価値のある企業になりました。しかし、ジョージタウン大学でAIを研究する学者ジェイコブ・フェルドゴイズ氏は、より多くの推論作業を行うことを期待している企業は、推論タスク用に最適化されたチップを使用することでパフォーマンスを向上させることができると述べた。
推論チップを専門とするメーカーには Google、Cerebras Systems、SambaNova などが含まれており、数十億ドル相当の受注が増加しています。 NVIDIA は、昨年 12 月に 200 億米ドルを投じてカスタム推論チップ企業 Groq の技術ライセンスを取得し、その優秀な人材を吸収した後、独自の推論専用プロセッサの発売を準備しています。
では、推論コンピューティングとは正確には何でしょうか?それはトレーニングに必要な計算とどう違うのでしょうか?なぜ需要はすぐに論理的なものになったのでしょうか?これは市場にとって何を意味するのでしょうか?
推論計算の原理
AI をレストランに例えることができます。モデルはシェフです。一定期間の集中的なトレーニングを経て、数百、あるいは数十億のレシピと調理技術を学習した後、注文を受け始める準備が整います。
理性はこのレストランの日々の運営です。ダイナーは注文を出し (通常はチャットボットへの質問の形で)、シェフが食事を準備します (チャットボットが応答を生成します)。
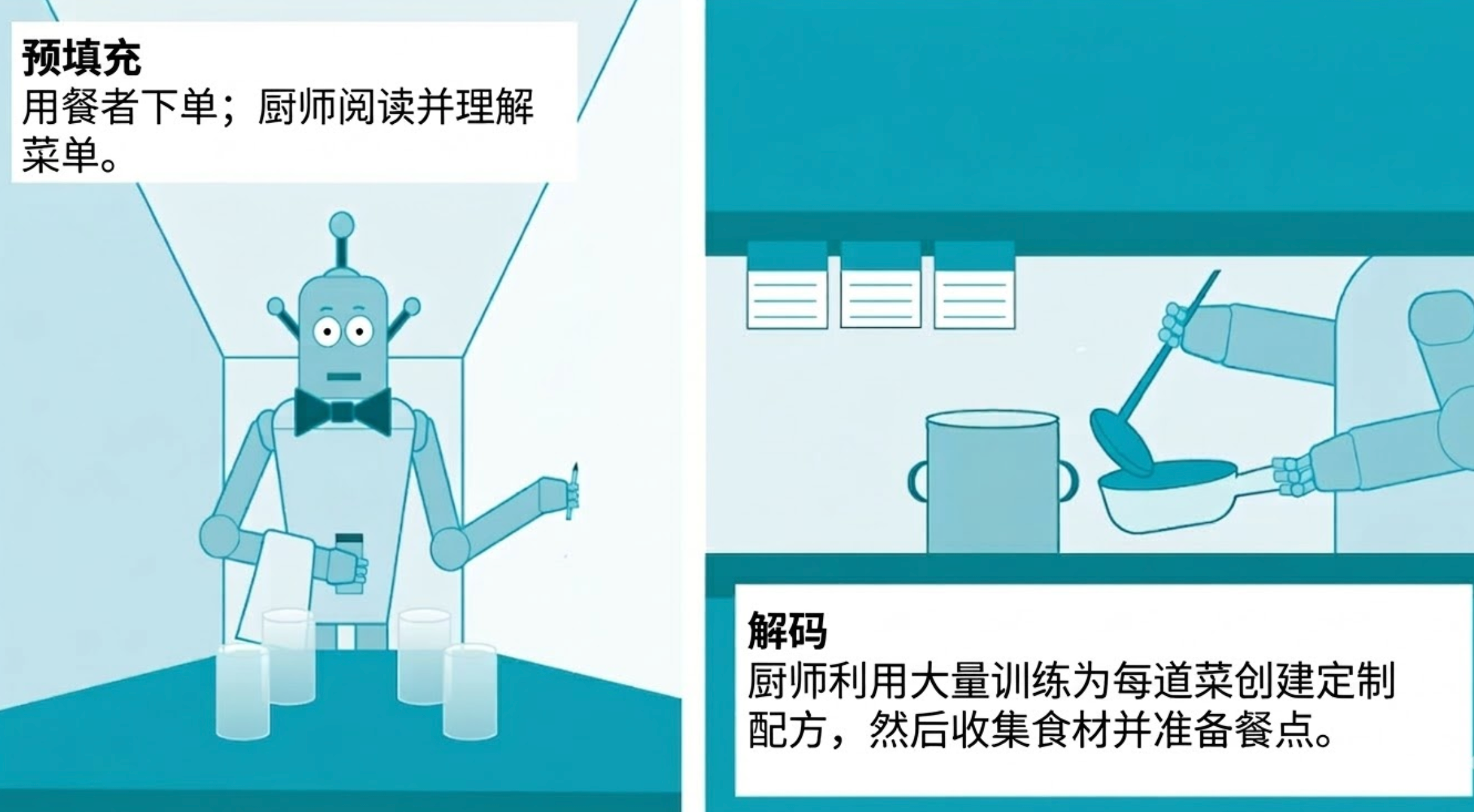
推論の原則
推論は、事前充填とデコードの 2 つの段階で構成されます。ユーザーがプロンプト単語を入力すると、事前入力フェーズが開始され、モデルはその中の各単語、記号、または画像を処理することによってユーザーのクエリを解釈します。
デコードは、モデルがトレーニング中に学習したすべてを使用してクエリ応答を生成するプロセスです。
これら 2 つの推論段階にはチップ上の異なる要件があります。事前設定段階ではより多くの処理能力が必要ですが、デコード段階ではより多くのメモリが必要です。これは、ユーザーに新しい「トークン」を提示するために蓄積された知識をすべて動員する必要があるためです。
単語要素とは何ですか?
トークンは、クエリを処理し、応答を生成するために使用されるデータの基本単位です。
データの種類によって変換範囲は異なりますが、一般的に 1 つの単語要素は英語の単語の約 4 分の 3 に相当すると考えられています。 「今日の天気はどうですか?」などの簡単なチャットボット クエリを考えてみましょう。例えば。モデルはそれを 6 ~ 8 個のトークンに解析します。
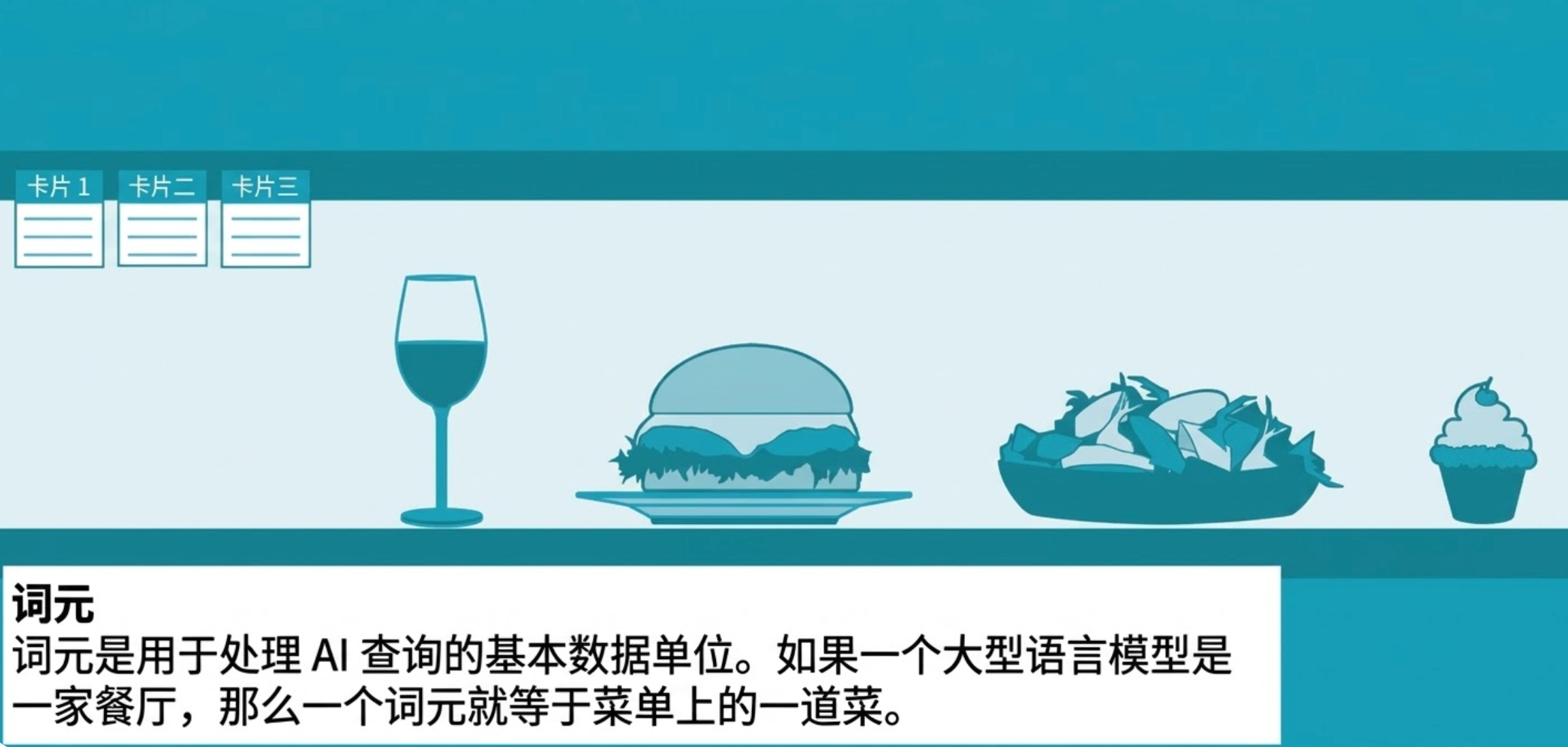
単語要素
通常、モデルは一度に 1 つの単語単位を生成し、解答がスムーズかつ合理的であることを保証するために、各単語単位を正しい順序で出力する必要があります。
現在、会計ソフトウェアから旅行予約サービス、画像生成ツールに至るまで、AI ツールを収益化しようとしている企業は、「1 ワットあたりのワード数/秒」や「1 ドルあたりのワード数/秒」などのコスト指標に夢中になっています。
チップメーカー GlobalFoundries の CEO、Tim Breen 氏は、このため、結果を効率的に出力する推論チップの能力が特に重要になっていると述べました。 「今日では、推論コストを削減することが鍵となります。」
トレーニングチップと推論チップの違い
トレーニングでは長期間にわたって大量のデータを処理する必要があるため、使用されるチップには強力な処理能力が必要であり、チップが配置されるデータセンターにはチップを冷却するための十分なエネルギーと水が確保されている必要があります。トレーニングにはメモリも必要ですが、GPU メモリが不十分な場合は、一部の処理タスクを他のチップに割り当てるか、既存のメモリが解放されるまで待つことができます。
対照的に、推論プロセスはオンデマンドで実行され、数週間ではなく数秒かかります。 「10 秒以上の間、ユーザーはすでに親指で電話画面をタップし始めており、次のことを行う準備ができています。」チップ設計会社SambaNovaの最高経営責任者(CEO)、ロドリゴ・リアン氏はこう語った。
したがって、推論チップには大容量の高帯域幅メモリを搭載する必要があり、待ち時間を短縮するためにデータセンターをユーザー クラスターの近くに配置する必要があります。また、Ayar Labs のようなチップ新興企業は、銅ケーブルよりも高速にデータを送信でき、冷却の必要性が少ない光ファイバー接続コンポーネントへの注目を高めています。
「今日では、推論のスケーリングがすべてです」と、Ayar Labs CEO の Mark Wade 氏は述べています。