
最近、一部のネチズンがBeanbaoを使用して中華民国の人物、李元紅を検索したところ、俳優ファン・ウェイのフォトショップ加工された写真が表示されました。 このウーロン事件は面白いように思えるかもしれませんが、実際には、画像認識と情報検索における AI の信頼性の抜け穴を暴露しました。多くのネチズンは、AIが十分に厳密ではなく、重要な歴史上の人物の検索で娯楽的なエラーが発生し、情報取得の精度に影響を与えたと不満を述べました。
公式の説明によると、ウーロン茶の起源はインターネット上で広まった誤解に由来しており、李元紅と范偉は容姿が非常に似ているという。 2010年の「党創立」のキャスティング時のパロディーPS写真は広く拡散され、その普及率は本物の歴史写真をはるかに上回った。一部の写真ギャラリーや百科事典が誤って含まれていたため、この人気の高い合成写真が AI 検索で優先されることになりました。
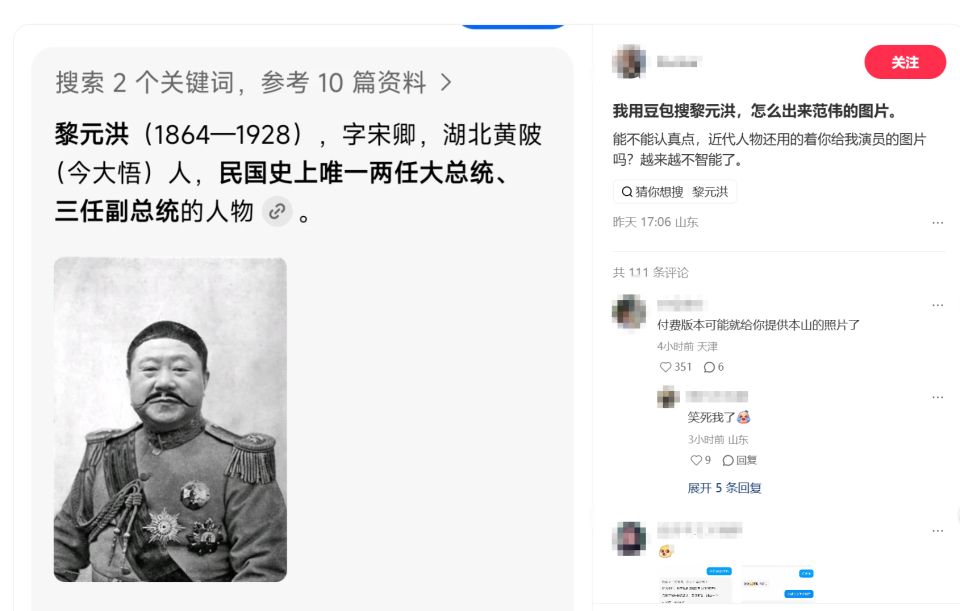
AIにおけるこのようなエラーの発生は、本質的に情報錯覚の典型的な現れです。
専門家は、大規模モデルはネットワークデータ学習に依存しており、自己検証機能が不足していると指摘しています。誤った情報がネットワーク上に繰り返し現れると、AIはそれを正しい結果として簡単に出力してしまい、「重大なナンセンス」の状況が発生します。
現在の技術では幻覚を完全になくすことはできません。エラー率を減らすには、データ ソースを最適化し、検索と検証を強化する必要があります。
この事件は、AIの信頼性についてネチズンの間でも議論を引き起こすきっかけとなった。他の歴史上の人物を検索するときにも同様のエラーが発生するのではないかと嘲笑する人もいます。一部のユーザーはAIのエラー情報に惑わされた経験を共有し、AIコンテンツの精度向上を訴えた。
現在、関連プラットフォームは検索ロジックを最適化し、インターネット上の誤った情報の干渉を減らすために、権威ある歴史的資料の画像をプッシュすることを優先しています。
