Google は本日、Gemini 3.1 Flash-Lite を正式に発売し、Gemini 3 シリーズの中で最も高速で最もコスト効率の高いモデルであると主張しました。また、3.1 Flash-Liteは開発者の大規模で高スループットのワークロード向けに設計されており、その価格帯とモデルレベルで非常に高い品質を示していると述べた。
本日より、3.1 Flash-Lite は Google AI Studio の Gemini インターフェイスを通じて開発者にプレビューとして提供され、企業ユーザーには Vertex AI を通じて提供されます。
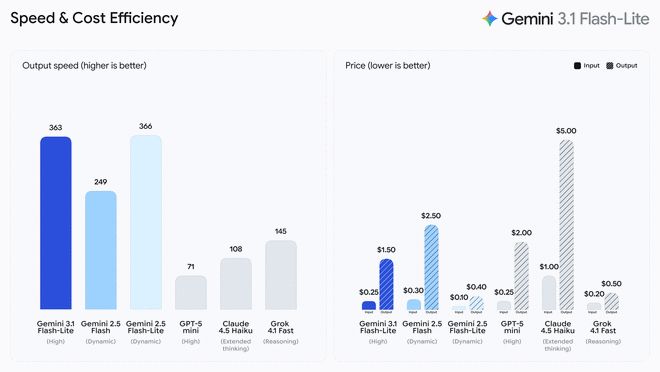
3.1 Flash-Lite の料金は、入力トークン (入力トークン) 100 万あたり 0.25 米ドル、出力トークン (出力トークン) 100 万あたり 1.50 米ドルです。 Artificial Analysis のベンチマーク テストによると、3.1 Flash-Lite は 2.5 Flash よりも同等以上の品質を維持しながらパフォーマンスが優れています。最初の単語の応答速度 (Time to First Answer Token) が 2.5 倍に向上し、出力速度も 45% 向上しました。 Google によれば、この低遅延機能は高頻度のワークフローには必須であり、開発者が応答性の高いリアルタイム エクスペリエンスを構築するための理想的なモデルとなっています。
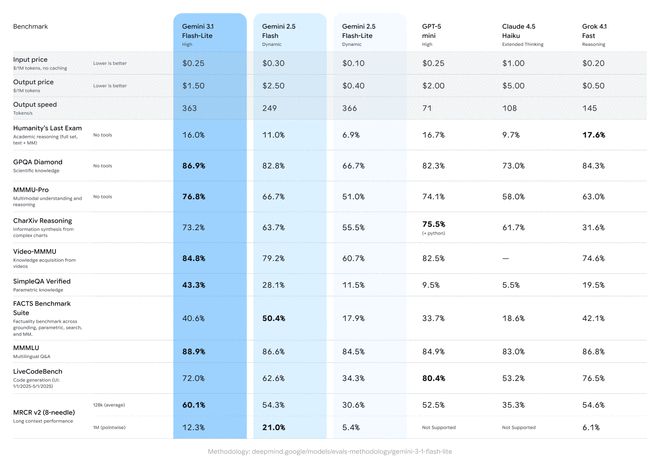
3.1 Flash-Lite は、Arena.ai リーダーボードで 1432 ポイントを獲得しました。推論やマルチモーダル理解のさまざまなベンチマーク テストにおいて、そのパフォーマンスは同レベルの他のモデルを上回ります。たとえば、GPQA ダイヤモンド テストでは 86.9%、MMMU Pro テストでは 76.8% のスコアを達成しました。このパフォーマンスは、2.5 フラッシュなどの前世代の大型モデルをも上回ります。
Gemini 3.1 Flash-Lite には、ネイティブ パフォーマンスに加えて、AI Studio および Vertex AI の「思考レベル」機能も標準装備されています。これにより、開発者は、モデルが特定のタスクについてどの程度深く「考える」かを制御できる柔軟性が得られます。これは、高頻度のワークロードを管理するために重要です。 3.1 Flash-Lite は、コスト重視の大量翻訳やコンテンツのモデレーションなどの大規模なタスクを処理できます。同時に、ユーザー インターフェイスやダッシュボードの生成、シミュレーション環境の作成、複雑な指示に従うなど、深い推論を必要とする複雑なタスクも実行できます。
Googleによると、AI StudioとVertex AIの早期アクセス開発者や、Latitude、Cartwheel、Wheringなどの企業がすでに3.1 Flash-Liteを使用して、複雑な問題を大規模に解決しているという。初期のテスターは、3.1 Flash-Lite の効率性と推論機能を強調しました。このモデルは大規模モデルと同等の精度で複雑な入力を処理でき、指示に厳密に従って高度な一貫性を維持できるという。