今年の I/O 開発者カンファレンスで、Google は新世代の Gemini 3.5 シリーズ モデルと新しい Gemini Omni シリーズを正式にリリースしました。 Gemini 3.5 Flash が最初に一般公開されたのに対し、Gemini Omni は「あらゆる入力からビデオを生成する」機能に焦点を当てています。
Gemini 3.5 Flash は、Gemini アプリの AI モードと Google 検索を通じてすべてのユーザーがすでに利用可能です。 Googleは、このモデルはFlashシリーズの一貫した高速性能を維持しながら、多くの面で大型フラッグシップモデルに匹敵するインテリジェンスレベルを備えていると主張している。
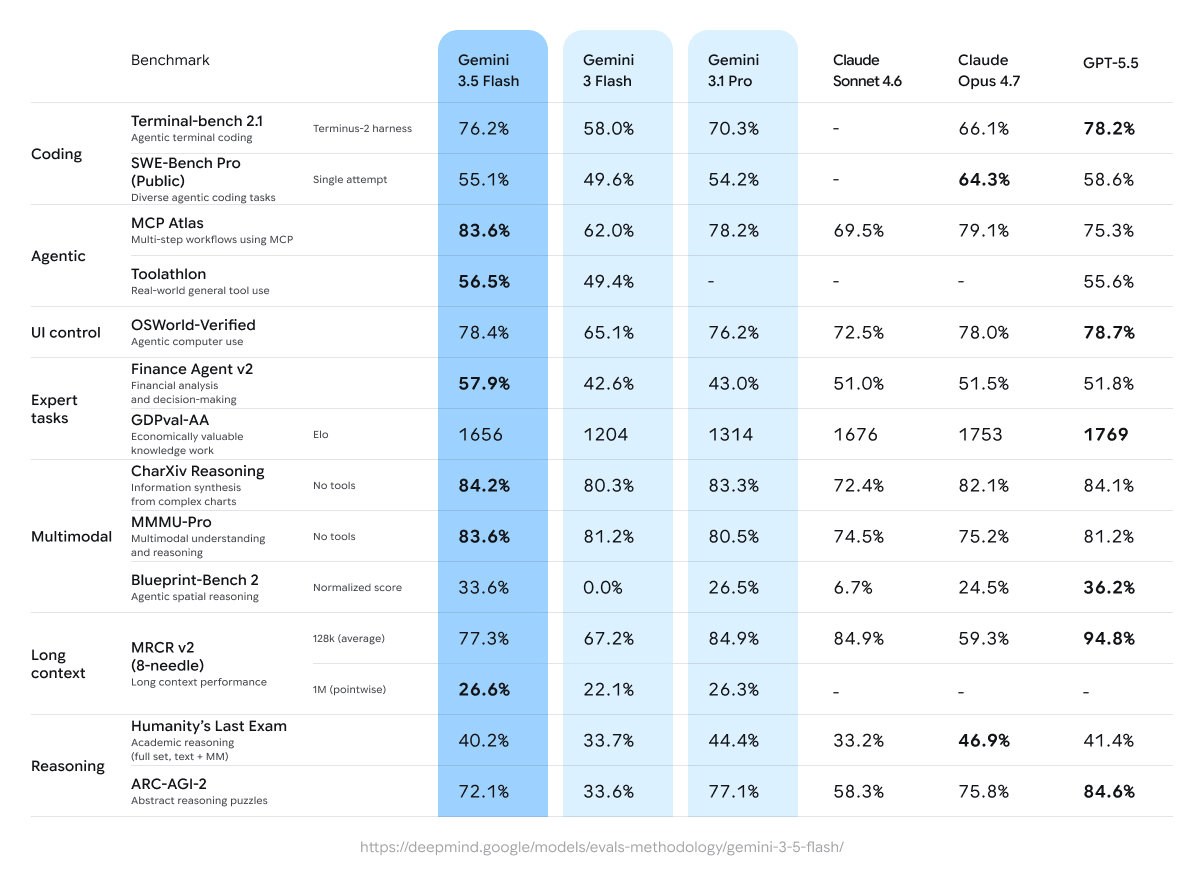
概要によると、Gemini 3.5 Flash は現在最も強力な Gemini エージェントおよびコード生成モデルです。複雑なコードやエージェントに関連するベンチマーク テストでも Gemini 3.1 Pro を上回り、マルチモーダルの理解においてリードを維持しているため、現在のデフォルト モデルとしても設定されています。ユーザーは、日常の検索、アプリ内会話、その他のシナリオでこのモデルを直接呼び出すことで、より迅速かつスマートな回答とコード サポートを得ることができます。
同時に発表された Gemini Omni は、生成ビデオの方向における Google の最新の試みを表しています。この新しいモデルは、あらゆる入力からビデオを生成できます。ユーザーは入力として画像、音声、ビデオ、テキストを自由に組み合わせることができ、モデルは Gemini の実世界の知識に基づいて高品質のビデオ コンテンツを生成します。生成が完了したら、ユーザーは自然言語を通じて複数ラウンドの会話編集を実行して、ビデオの詳細を変更および微調整することもできます。
Gemini Omni シリーズの最初のモデルは Gemini Omni Flash です。これは、ビデオの部分的または全体的な変更をサポートし、複数回の作成中に元のシーンの物語の一貫性を維持し続けることができるため、ユーザーはメインのストーリー ラインを失うことなく継続的に調整することができます。 Googleによれば、このモデルは重力、運動エネルギー、流体力学などの物理概念をより直観的に理解しており、より現実的で信頼性の高いダイナミックなシーンを生成できるとしている。
クリエイティブ エクスペリエンスの面では、Gemini Omni を使用すると、ユーザーは自分の声とアバターを使用してビデオ作成に参加でき、それによって個人の特徴を持つデジタル アバターを生成できます。合成コンテンツのトレーサビリティとセキュリティの問題に対処するために、このモデルで生成されたすべてのビデオには、AI 生成コンテンツのラベル付けと識別のための SynthID 電子透かしが埋め込まれます。
入手可能性の点では、Gemini Omni Flash は本日より世界中の加入者に提供されます。 Google AI Plus、Pro、Ultra プランに加入しているユーザーは、Gemini アプリと Google Flow でモデルを直接使用できます。同時に、Google はこの機能を YouTube Shorts と YouTube Create にも無料で導入し、より多くのクリエイターが主流のコンテンツ プラットフォームで Gemini テクノロジーに基づくビデオ生成機能を体験できるようにします。