先週の Cloud Next カンファレンスで、Google は Gemini 2.5 Flash モデルが間もなく登場し、大幅な改善がもたらされると発表しました。本日、Google は、Google AI Studio および Vertex AI を介して Gemini API の Gemini 2.5 Flash プレビューを発表しました。この新しいモデルは、Gemini ユーザーもモデル セレクターを通じて利用でき、Canvas と連携してドキュメントとコードを簡単に最適化できます。

前世代の Gemini 2.0 フラッシュに続き、Gemini 2.5 フラッシュはコストと遅延を削減しながら推論機能を大幅に向上させました。 Googleは、この新モデルはコストパフォーマンスに優れていると主張している。具体的な価格は以下の通りです。
100 万入力トークンあたり 0.15 ドル
100万生産あたり単語要素$0.60 を請求します (理由は必要ありません)
100 万出力トークンあたり 3.50 ドル (推論を含む)
これは Flash 2.5 の初期バージョンですが、すでに Flash 2.0 バージョンと比較してパフォーマンスが大幅に向上しています。
必要に応じて、思考機能を完全にオフにして、このモデルを Flash 2.0 のドロップイン代替品として使用することができます。
Gemini API、AI Studio、Vertex、Gemini アプリで利用できます。
— ローガン・キルパトリック (@OfficialLoganK)
Gemini 2.5 Flash は、Google 初の完全ハイブリッド推論モデルであり、開発者は推論のオンとオフを選択できます。これは、開発者が目標の品質、コスト、待ち時間に基づいて応答を最適化するのに役立つと言われています。この新しいモデルのベンチマークを以下でチェックしてください。
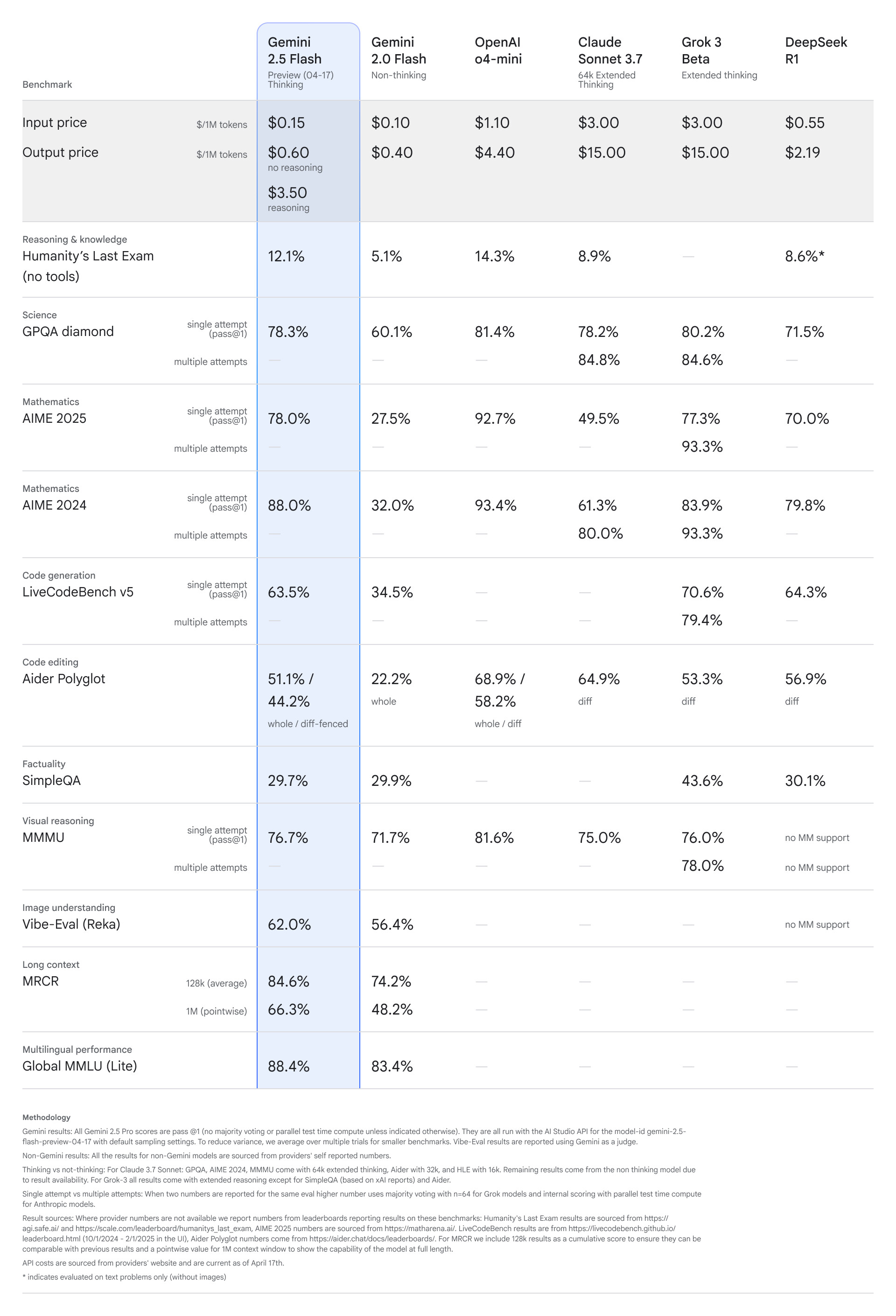
上の表が示すように、Gemini 2.5 Flash は、その低コストにも関わらず、Anthropic や Grok の最先端のモデルに対して依然として優位性を保っているようです。 OpenAI が最近リリースした o4-mini は、Gemini 2.5 Flash プレビューよりもパフォーマンスが優れているようですが、価格ははるかに高くなります。