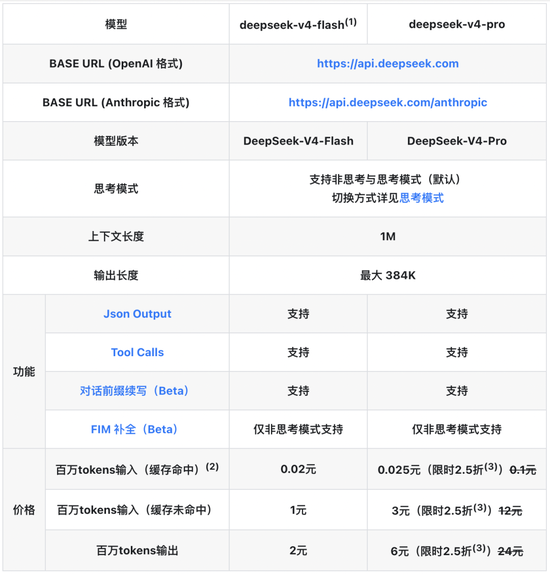
DeepSeek は、大規模モデルの包含の境界を再定義しています。 4 月 26 日、DeepSeek は API 価格調整の発表を正式にリリースしました。すべての API 入力キャッシュ ヒットの価格が、初期価格の 10 分の 1 に引き下げられました。 V4‑Pro アップグレードは期間限定で 25% オフで、100 万トークンの入力キャッシュ ヒットは 0.025 元という低価格で、世界の大型モデルの価格の新安値を打ち立てています。

DeepSeek の公式 API 価格ページの発表によると、この値下げは V4 シリーズのすべてのモデルを対象とし、主要な調整は入力キャッシュ ヒット シナリオに焦点を当てています。その中で、DeepSeek-V4-Flash 入力キャッシュのヒット価格は、0.2 元/100 万トークンから 0.02 元/100 万トークンに下がりました。
エンタープライズ レベルのユーザー向けの DeepSeek-V4-Pro には、さらに大きな割引があります。キャッシュ入力の場合、元の価格 100 万トークンあたり 1 元が 0.1 元に減額されます。 2026 年 5 月 5 日までに 25% オフの期間限定特別オファーが追加されますが、実際には 100 万トークンあたりわずか 0.025 元です。キャッシュミス入力は 12 元から 3 元に削減され、出力は 24 元から 6 元に削減されます。
画像出典:DeepSeek公式サイト
DeepSeek は、DeepSeek-Chat と DeepSeek-Reasoner の 2 つのモデル名が将来廃止される予定であると述べました。互換性の理由から、この 2 つはそれぞれ DeepSeek-V4-Flash の非思考モードと思考モードに対応します。
価格調整前後の価格を比較すると、高頻度通話や長文処理シナリオのコストが 90% 以上低下していることが簡単にわかります。 RAG ナレッジ ベース、インテリジェントなカスタマー サービス、ドキュメント分析などのキャッシュ ヒット率が高いアプリケーションは、商業コストの崖のような低下を直接実現でき、AI の大規模実装のコストの束縛を打ち破るのに役立ちます。
DeepSeek の大幅な価格引き下げは、DeepSeek‑V4 の技術アップグレードと Shengteng エコシステムとの緊密な連携に関連しています。
4 月 24 日、DeepSeek‑V4 のプレビュー版が正式にリリースされました。オープンソースの Pro モデルと Flash モデルはどちらも、100 万トークンの超長いコンテキストをサポートします。自社開発のスパース アテンション アーキテクチャにより、推論コンピューティング能力の消費が大幅に削減されます。 Pro バージョンのシングル トークンのコンピューティング能力は V3.2 のわずか 27% であり、KV キャッシュは 10% に削減され、コストの最適化をボトムアップで実現します。
DeepSeek によって発表されたパラメータは、DeepSeek‑V4‑Pro が 49B のアクティベーション パラメータと 33T の事前トレーニング データを備えており、高性能のフラッグシップとして位置付けられていることを示しています。 DeepSeek‑V4‑Flash には 13B のアクティベーション パラメータと 32T の事前トレーニング データがあり、高速性と低コストに重点を置いています。
前世代モデルと比較して、DeepSeek-V4-Pro のエージェント機能が大幅に強化されました。エージェント コーディングの評価では、V4-Pro は現在のオープン ソース モデルの最高レベルに達しており、他のエージェント関連の評価でも良好な成績を収めています。 DeepSeek-V4 は、DeepSeek の社内従業員が使用するエージェント コーディング モデルになっていると報告されています。評価フィードバックによると、使用体験は Sonnet 4.5 よりも優れており、配信品質は Claude Opus 4.6 非思考モードに近いですが、Opus 4.6 思考モードとはまだ一定のギャップがあります。
世界のナレッジ評価では、DeepSeek-V4-Pro は他のオープンソース モデルを大きく上回っていますが、トップのクローズド ソース モデルである Gemini-Pro-3.1 にはわずかに劣っています。数学、STEM、競合コードの評価において、DeepSeek-V4-Pro は現在公的に評価されているすべてのオープンソース モデルを上回り、世界トップのクローズド ソース モデルに匹敵しました。
DeepSeek-V4-Pro と比較すると、世界知識の蓄積という点では DeepSeek-V4-Flash は若干劣りますが、緻密な推論能力を示します。モデルのパラメーターとアクティベーションが小さいため、V4-Flash はより高速で経済的な API サービスを提供できます。
また、DeepSeek-V4 は、トークン次元で圧縮し、それを DSA スパース アテンション (DeepSeek Sparse Attendance) と組み合わせる新しいアテンション メカニズムを開拓して、世界をリードするロング コンテキスト機能を実現し、従来の方法と比較してコンピューティング メモリとグラフィックス メモリの要件を大幅に削減します。
さらに注目すべき点は、Ascend スーパー ノード製品全体が DeepSeek V4 シリーズ モデルをサポートしていることです。これは、DeepSeek がより多くのローカリゼーション信号をリリースすることも意味します。
DeepSeek-V4 は技術レポートで次のように述べています。「きめ細かい EP (Expert Parallel) スキームは、NVIDIA GPU と Huawei Ascend NPU の 2 つのプラットフォームで検証されました。強力な非融合ベースラインと比較して、このスキームは一般的な推論タスクで 1.50 ~ 1.73 倍の高速化を達成しました。遅延に敏感なシナリオ (強化学習 (RL) ロールアウトや高速エージェント サービスなど) では、最大で 1.50 ~ 1.73 倍の高速化を達成できます」加速度1.96倍。」
DeepSeek は、今年下半期に Ascend スーパーノード製品の全製品が一括して発売されるため、Pro バージョンの価格が大幅に引き下げられることが予想されると強調しました。
DeepSeek-V4 のリリース後、ゴールドマン サックスは、DeepSeek V4 の中心的な重要性は、より複雑なエージェント アプリケーションの実装を低コストでサポートし、それによって AI アプリケーションの規模に新たな余地を開くことであると指摘する分析レポートを発表しました。ゴールドマン・サックスは、Ascend スーパーノードの導入により、DeepSeek のコスト競争力がさらに強化され、より幅広い用途に適用できる条件が生まれると考えています。さらに、継続的なチップ引き締めを背景に、中国のトップ AI モデルを国内のコンピューティング能力に移行する傾向が、主要企業によって明確に支持されています。
ゴールドマン・サックスの報告書はまた、テンセントとアリババがディープシークへの評価額200億ドル以上で投資交渉を行っているとの報道も引用している。 ZhipuとMiniMaxの最新の市場価値は、それぞれ約530億米ドルと310億米ドルです。この潜在的な取引は、希少なトップレベルのAI能力をめぐる巨人の競争の論理を反映している。
Huatai Securities は、市場は V4 を「コスト削減とコンピューティング能力とストレージ要件の削減」として容易に解釈すると考えていますが、より重要な限界的な変化は、長いコンテキストのコストが減少した後、複雑なエージェント、複数ドキュメントの分析、長期タスク、オンライン学習などのシナリオの可用性が増加し、推論呼び出しの数とストレージのアクセス頻度が拡大すると予想されることです。