今年 9 月、Google Search Console を使用している一部の開発者は、Web サイトの検索トラフィック レポートに、以前の短い検索用語の代わりにチャットのようなテキストが表示されるという異常を発見しました。これらの新しいエントリは、サイトの通常の検索訪問者のリクエストではなく、個人的な質問や仕事関連の質問についてのユーザーとチャットボットの間のプライベートな会話のように見えます。
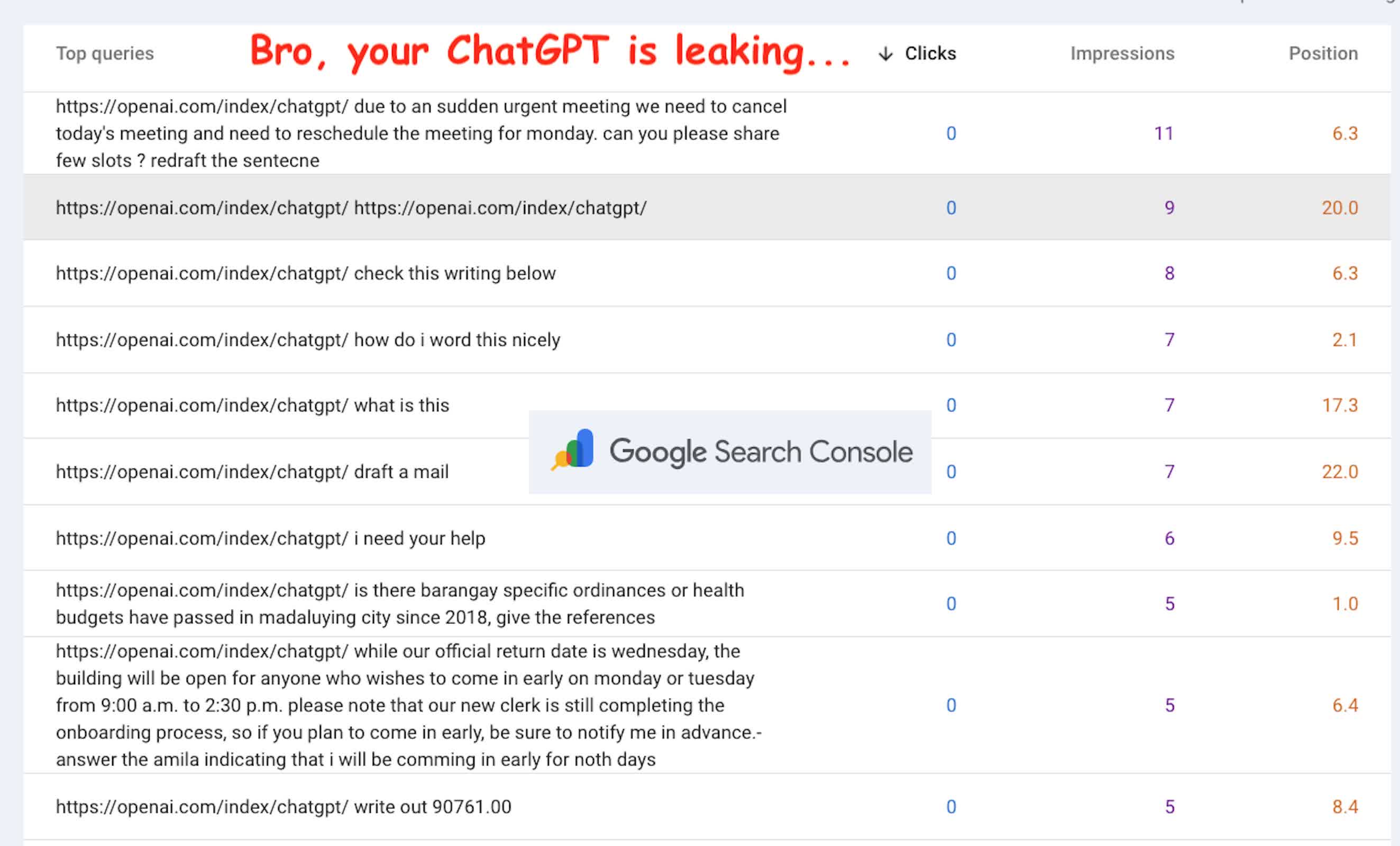
Google Search Console はもともと、ユーザーが Google 検索を通じて Web サイトにどのようにアクセスするかを示すために使用されていました。 Web サイト管理者がショックを受けたのは、新しいコンテンツは検索用語とはまったく似ておらず、トラフィック分析データのみが含まれるはずのシステムにログインしているチャットボットとのプライベートな会話のように見えたことです。
この異常事態は、分析会社Quantableの創設者であるJason Packer氏が同社のブログで初めて公表した。ウェブサイト最適化コンサルタントの Slobodan Manić と協力して、彼は数週間かけて実験を再現し、さまざまな入力をテストし、ChatGPT の検索機能と Google のインデックス システムとの相互作用を追跡しました。最終的な調査結果では、「単なる故障」をはるかに超えたプライバシーリスクが明らかになりました。
Packer 氏と Manić 氏のテストによると、一部の ChatGPT セッションはユーザー プロンプトを誤って Google 検索にルーティングします。彼らはそれを、流出したコンテンツの冒頭に繰り返し現れる特定の URL パターン (https://openai.com/index/chatgpt/) にまで遡ることを突き止めました。 Google がアドレスの単語分割を実行すると、「openai」、「index」、「chatgpt」に解析されます。これらの単語で上位にランクされている Web サイトでは、ChatGPT ユーザー プロンプトの一部が Search Console バックエンドに記録されていることがわかります。
言い換えれば、ChatGPT によって送信されたユーザー ヒントが外部検索をトリガーした場合、Google はそのヒント自体を検索語として記録することがあります。影響を受けるサイトの管理者にとって、漏洩したプロンプトワードはトラフィックデータとしてバックグラウンドで表示されます。
OpenAIはこの問題を認め、「少数の検索に一時的に影響を与えたルーティングの不具合」と呼び、詳しい説明はせずに修正されたと述べた。 Packer氏は、OpenAIの迅速な修正を歓迎したが、ChatGPTが対応を強化するためにGoogleの検索結果をスクレイピングし続けていたことがこのインシデントによって確認されたかどうかという、より大きな問題には同社が対処していないと指摘した。
この問題は、GPT-5 モデルの新バージョンで ChatGPT によって導入された「Web ブラウジング」動作に関係しています。プロンプトに最新情報または外部情報が必要であるとシステムが判断すると、Web 検索がトリガーされます。しかし、Packer と Manić は、チャット インターフェイスの 1 つのバージョンに「hints=search」パラメータがあり、ほぼ毎回検索がトリガーされることを発見しました。
また、入力ボックスのバグにより、リファラー URL がすべてのクエリに追加されていました。このようにして、ChatGPT が検索を実行するたびに、Google は URL だけでなくユーザーのプロンプトも記録します。 Search Console は検索文字列全体を追跡するため、関連するサイト所有者にユーザー プロンプトが「完全に表示」されます。
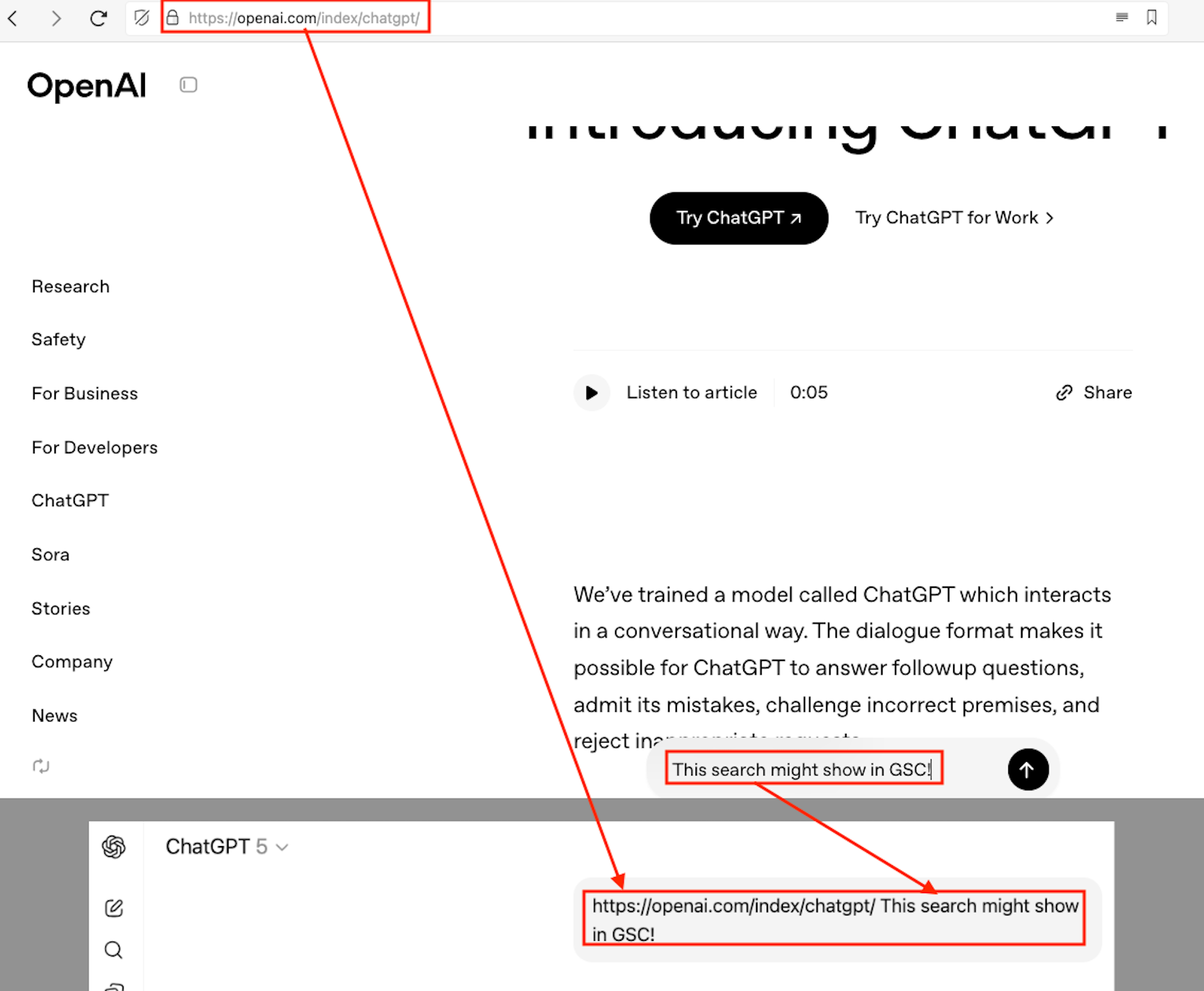
Packer 氏は、このシステムはプライベート API や内部データ チャネル (Search Console には表示されない) を介するのではなく、Google のインデックス作成インフラストラクチャと直接やり取りしていると考えています。この予期せぬ可視性は、ChatGPT がライブ Google 検索を実行し、ユーザー入力を Google およびすべての関連サイトに公開していることを実際に示しています。
OpenAIは、流出した検索リクエストはごく少数だとし、具体的な数字は明らかにしていないため、週間アクティブユーザー7億人のうち何人が影響を受けたのかはまだ明らかになっていない。
以前は、ユーザーが ChatGPT へのパブリック リンクが Google のメイン Web サイトに含まれていることに気づくという問題がありました。その際、OpenAIはユーザーが誤って共有スイッチを操作したと主張した。この場合、Packer 氏は、ユーザーのアクションが漏洩を引き起こしたわけではないと強調しました。同氏はArs Technicaのインタビューで、「同意メカニズムは関与していない」と語った。 「誰も『共有』をクリックしなかったため、プロンプトの言葉が誤って送信されました。」公開ページとは異なり、Search Console のエントリは影響を受けるユーザーが手動で削除できないため、コンテンツは関連キーワードでランク付けされている Web サイト所有者に常に公開されます。
研究者らは、この異常が、検索エンジン分析界で「ワニの口」として知られる現象、つまりSearch Consoleのグラフ上でインプレッション数が急増する一方でクリック数が減少する現象にも関連しているのではないかと考えている。 OpenAI システムが大量の合成クエリで Google に繰り返しクエリを実行すると、これらの分析データが歪曲される可能性があります。
Packer 氏と Manić 氏は、OpenAI の修正があらゆる種類のプロンプト ワード リークを完全にブロックするのか、それとも特定の URL ルーティング メカニズムのバグのみを解決するのかをまだ確認できていません。引き続き注意が必要だとした。 「特定のインターフェースにのみ影響するのか、それともより広範囲の会話に影響するのかはまだ分からない」とパッカー氏は語った。 「要するに、これは、これらの AI ツールの背後にあるシステムによるユーザー データの処理には、依然として多くの制御不能で予測不可能なリスクが存在することを思い出させます。」