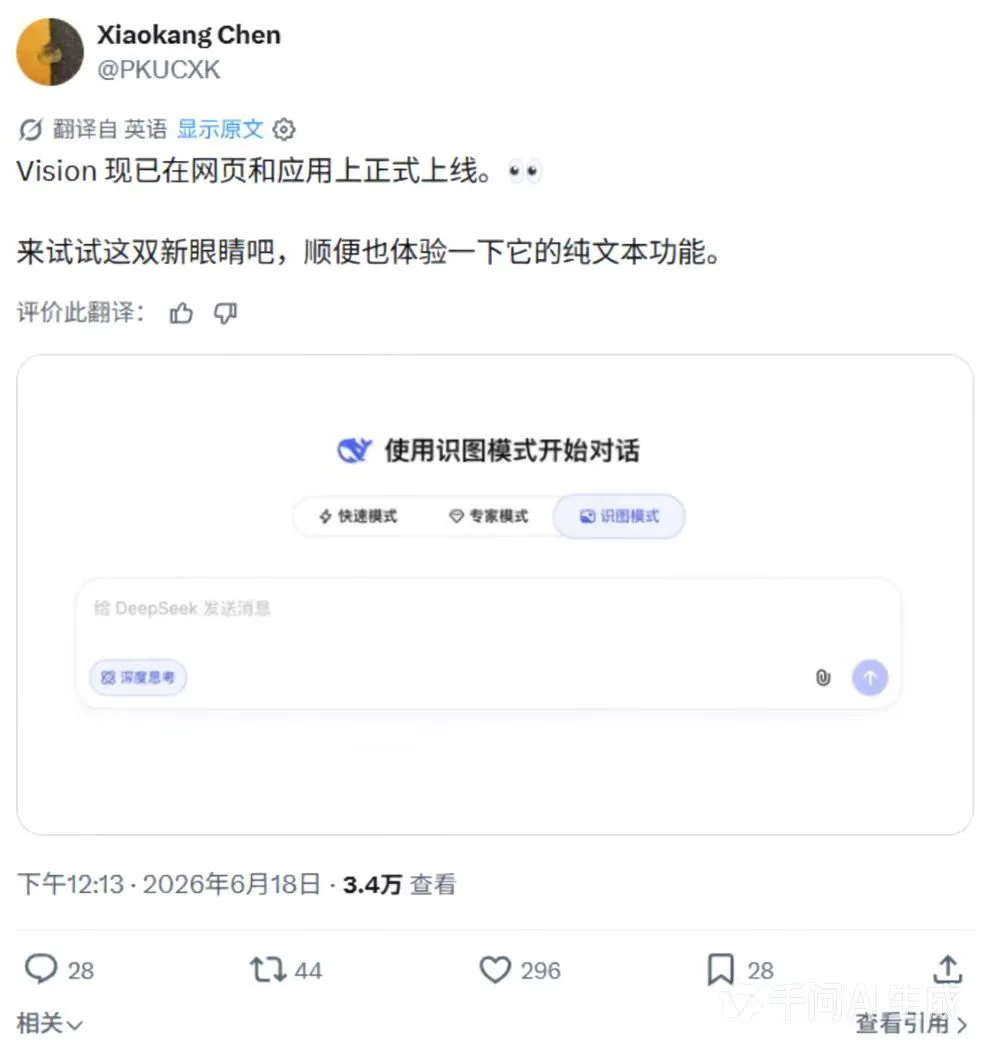
6月18日、DeepSeekマルチモーダル研究者のChen Xiaokang氏は、DeepSeekの画像認識モードがウェブとアプリで正式に開始されたと投稿した。クエリでは、DeepSeek のアプリ側の画像認識モードでは依然として「画像理解機能は内部テスト中です」というプロンプトが表示されることがわかりましたが、Web ページにはそのようなプロンプトはありません。
ただし、メディアのテストでは、DeepSeek は人物を識別する精度が低いことが判明しました。たとえば、上司の梁文峰を認識できなかった。ある瞬間には彼を王興として認識し、また別の瞬間には彼を別人として認識しました。


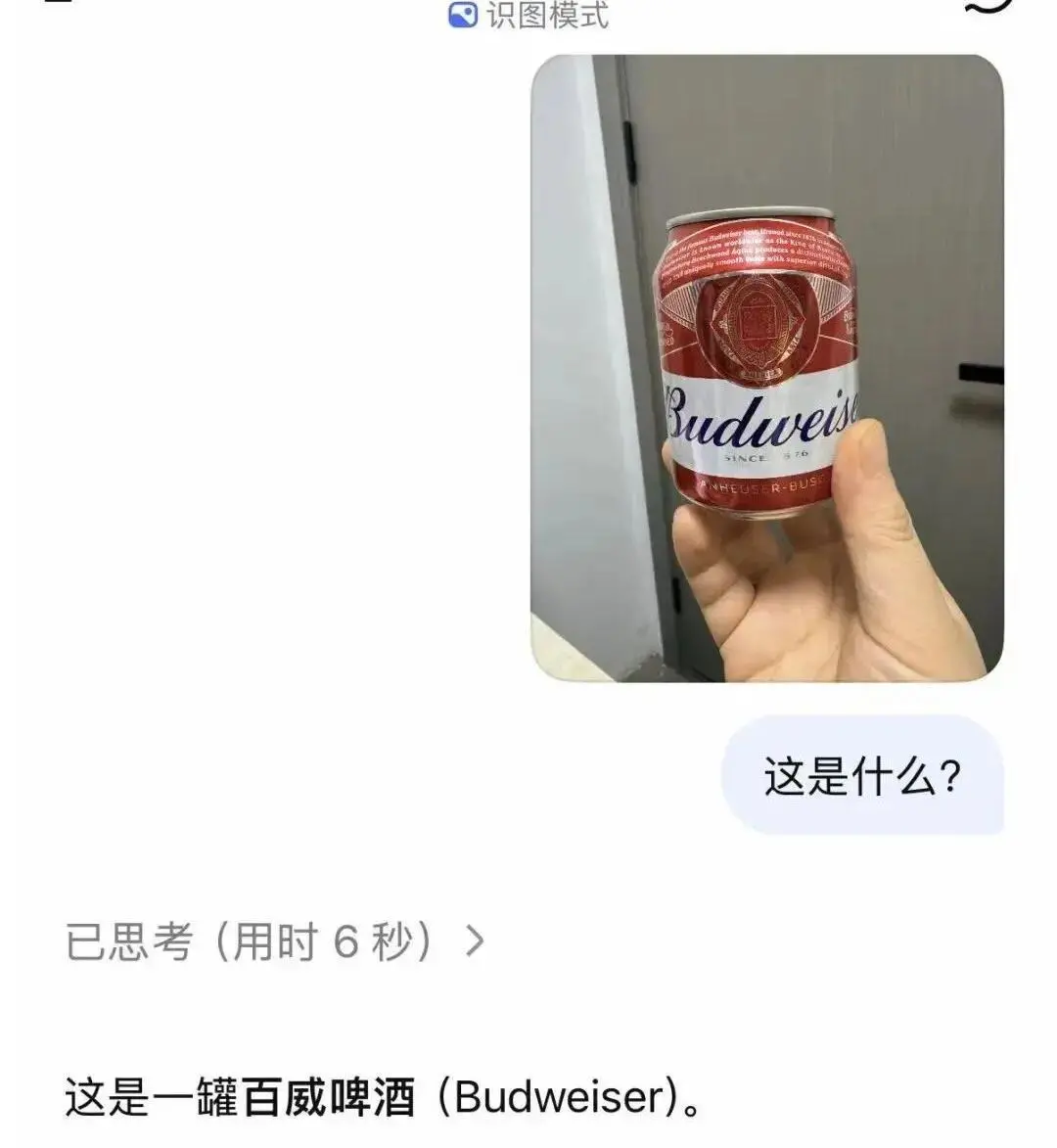
ただし、一般的な物体やよく知られている建物の識別は比較的正確です。
レポートによると、2 か月前、DeepSeek 画像認識モードがグレースケールで正式に開始されました。ネイティブのビジュアル インタラクション ポータルとして、DeepSeek 画像認識モードは、高速モードおよびエキスパート モードと並ぶ独立した第 1 レベルの機能です。初期の純粋なテキスト モデルの機能制限を完全に取り除き、画像とテキストを使用した統合された対話エクスペリエンスを実現します。
DeepSeek 画像認識モードは単純な画像テキスト抽出ツールや単純な OCR ツールではなく、完全な視覚理解閉ループを構築するために自社開発した DeepSeek-OCR2 視覚因果フロー メカニズムに依存していることに注意してください。ユーザーはテキストの質問を含む写真を直接アップロードするだけで、システムは物体認識、シーン分析、チャートの分解、細かいテキストの抽出、詳細マイニングを同時に完了できます。
DeepSeekは最近シリーズA資金調達を完了し、資金調達額は約510億元、投資後の企業評価額は約4000億元となったと報じられている。