6 月 27 日、DeepSeek は DSpark 技術レポートと DeepSpec コードベースをリリースしました。 DeepSeek-V4 のベースモデルは変更されていません。新しいのは、サーバー側の投機的デコード モジュールである DSpark です。 DeepSeek は、HuggingFace モデル ページで非常に率直に述べています。V4-Pro-DSpark と V4-Flash-DSpark は「新しいモデルではありません」。これら 2 つのページは、同じモデル チェックポイントと、デコードされたモジュールを推測した後のサービス バージョンを指します。

これは、DSpark によってモデルが突然スマートになるわけではないことを意味します。これは、モデルがオンラインになった後、いかにしてより速く、より安価に答えを吐き出すかを目的としています。
技術レポートには、DSparkがDeepSeek-V4のオンラインサービスシステムに導入されていると記載されています。実際のユーザー トラフィックでは、DeepSeek の前世代のオンライン投機生成ソリューションである以前の MTP-1 運用ベースラインと比較して、スループット条件が一致する場合、V4-Flash のユーザーごとの生成速度は 60% ~ 85% 向上し、V4-Pro は 57% ~ 78% 向上しました。
ここでの「速さ」も和らげる必要があります。これは主に生成段階、つまりモデルがトークンを出力し続ける速度を指します。すべてのユーザー要求のエンドツーエンドの応答時間が 85% 高速になるという意味ではありません。長いプロンプト単語の事前入力、取得、ツールの呼び出し、キューイング、およびネットワーク遅延は、ユーザーが実際に待つ時間に影響します。
モデルがオンラインになった後も、推論アカウントが残ります
これは新モデルのリリースほど活発ではありませんが、AI 企業が日々直面している現実に近いものです。コストはモデルがトレーニングされた後も終了しません。
チャットボット、コード アシスタント、エージェント、および検索ベースの製品は、呼び出しのたびに GPU 時間を消費し続けます。モデルが遅い場合、ユーザーはより長く待つ必要があります。推論のコストが高くなると、メーカーが高品質のモデルをより多くのシナリオに公開することがより困難になります。
AI 業界は過去 2 年間で、企業が購入する必要がある GPU の数、構築するクラスターの規模、次世代モデルのトレーニングにかかる費用など、トレーニング コストについて議論することに慣れてきました。しかし、モデルが実際に製品になった後は、推論という別の種類のコストが発生し続けます。
トレーニングは大きなプロジェクトのようなもので、推論は公共料金の請求書のようなものです。ユーザーが質問をし続け、エージェントがタスクを実行し、コード アシスタントがパッチを生成している限り、モデルはコンピューティング パワーを消費し続けます。
大規模モデルのサービスは、最終的には速度とトークン コストの 2 つの指標に戻ります。 API の価格設定ページは通常、入力トークンと出力トークンに基づいて料金を請求し、企業は内部でさまざまなモデル、キャッシュ、ルート、コンテキストの長さをコスト項目に分割することもあります。
DSpark を直接価格の削減に結び付けることはできませんが、同じ GPU クラスターにより、ユーザーが同様のスループットでより速く回答を得ることができる場合、同じハードウェアでより多くのユーザーにサービスを提供できる、またはより少ないカードで同じユーザー エクスペリエンスを提供できることを意味します。
「まず推測してからテストしてください」
投機的デコードの考え方は、「まず推測してからテストする」と大まかに理解できます。
大規模なモデルがテキストを生成する場合、通常はトークンを次々に吐き出します。前のトークンが出た後、次のトークンは何を拾うべきかがわかります。この方法は安定していますが、時間がかかります。投機的デコードにより、軽量のドラフト モジュールが事前に候補トークンを推測できるようになり、ターゲットの大規模モデルがバッチで検証されます。正しい推測はそのまま受け入れられ、間違った推測は修正されます。
小さなモデルは大きなモデルに対する決定を下すことができません。どのトークンが最終的に受け入れられるかは、ターゲット モデルによって検証されます。正しく実装された場合、生成方法が変更されますが、ターゲット モデルの出力分布は変更されません。高速化は、大規模なモデルで候補を段階的に検証するのではなく、バッチで検証することで実現します。
DSpark が変更したのはドラフトの生成方法です
この論文は「最初に推測してからテストする」という説明にとどまりません。ドラフトの作成方法に焦点を当てています。

既存の戦略草案は、大きく 2 つのカテゴリーに分類されます。自己回帰ドラフト機能は、後のトークンが前のトークンを参照するため、より安定していますが、ドラフトが長くなると遅延も増加します。平行ドラフターはより高速で、段落全体を一度に推測できますが、各位置は個別に推測されます。後のトークンは前のトークンから切り離されやすく、遅くなるほど受け入れ率が低下する可能性が高くなります。
DSpark は妥協を選択します。論文のタイトルにあるキーワードは「半自己回帰世代」です。まず並列メソッドを使用して候補を提案し、次に軽量のシーケンシャル層を使用して後続のトークンの条件関係を変更します。これにより、並列生成の速度が維持されるだけでなく、後続の候補者が以前に推測された内容を確認できるようになります。

もう 1 つの重要な点は、検証にかかる期間です。
推測する候補トークンが多ければ多いほど、節約できる額は少なくなります。後半が拒否される可能性が高いとわかっていても、それを検証のために大規模なモデルに渡す場合、価値の低い位置に GPU 時間を費やしていることになります。DSpark は、候補の信頼性と現在のシステム負荷を調べて、検証の長さを動的に決定します。GPU が空の場合は、複数のテストを実行できます。負荷が高い場合、コンピューティング能力は受け入れられる可能性の高い部分に確保されます。
これが、論文のタイトルにある「Confidence-Scheduled」が言いたいことです。

DSpark は既存の技術的ルートに基づいています
DSpark は、既存のデコード ルートを推測した後に存在し、DeepSeek がこの技術的なルートをオンライン サービスにプッシュした後の公開リファレンスのようなものです。
SpecInfer は、早ければ 2023 年に小規模モデルの予測、トークン ツリー、並列検証を大規模モデル サービス システムに導入します。 Medusa は、2024 年にモデルに複数のデコード ヘッドを追加して、後続の複数のトークンを一度に予測することを提案しました。 EAGLE シリーズは、ドラフト モデルとダイナミック ドラフト ツリーに関する合格率を向上し続けています。 vLLM、SGLang、TensorRT-LLM などの推論フレームワークは、長い間、投機的デコードをレイテンシを短縮するための重要なツールとしてみなしてきました。
DSpark の利点は、ドラフトの生成方法、候補の一貫性を保つ方法、負荷に応じて検証の長さがどのように変化するか、実際のオンライン トラフィックの下でどの程度速度を向上できるかなど、いくつかの運用上の問題をまとめて処理できることです。
論文内で繰り返し登場するキーワードも、「モデルの機能向上」から、ユーザーごとの生成速度、一致したスループット、サービス レベル アグリーメント (SLA) などのサービス側の用語に移りました。
これは、最大の数値を選択して調べることができない理由も説明しています。この論文には確かに 661% や 406% などの高スループット データがありますが、これらはより厳しいユーザーごとの速度目標から来ています。その設定の下では、古いベースライン自体がすでにサービス機能の境界に近く、DSpark の相対的な優位性が増幅されます。
通常の利点を実際に示すことができるのは、一致するスループット、実際のトラフィック分散、および比較オブジェクトである MTP-1 という前の一連の数値です。
DeepSpec では何を再現できるのでしょうか?
DeepSeek は DeepSpec もオープンソース化しました。これは、投機的デコーディング ドラフト モデルをトレーニングおよび評価するためのコード ライブラリです。これにはデータの準備、トレーニング、評価プロセスが含まれており、Qwen3、Gemma、その他のモデルに関連するチェックポイントもリリースされます。
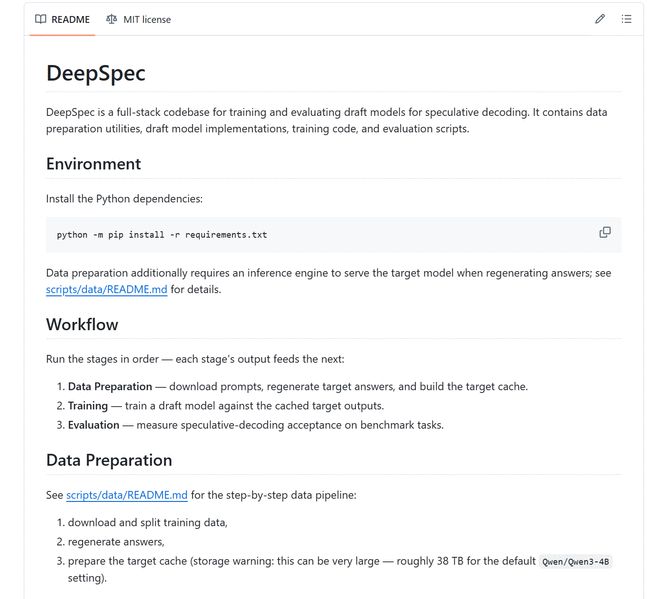
しかし、オープンソースは「ダウンロードして複製する」という意味ではありません。プロジェクトのドキュメントによると、デフォルトの Qwen3-4B 構成では、ターゲット モデルのキャッシュが 38TB 近くになる可能性があります。デフォルトのトレーニング スクリプトは、単一ノード上に 8 つの GPU を想定しています。論文の結果を一致させるには、トレーニング設定が厳密に一貫している必要があり、特定の領域でドラフト モデルをさらに微調整する必要があります。
外部の世界はメソッドの一部を検証でき、DeepSpec を他のオープンソース モデルに移植することもできますが、DeepSeek-V4 オンライン サービスにおける一連の速度向上の数値は依然として DeepSeek 独自のハードウェア スケール、トラフィック分散、実稼働システムのスケジューリングから得られます。
オープンソースは環境ではなく方法です。
コミュニティが最も懸念しているのは、繰り返し発生する境界線です
に関する議論
AI 研究者の Ravid ShwartzZiv 氏は、DSpark を 2 種類のドラフター間の妥協点として要約しています。パラレル ドラフターは高速ですが、候補ブロックに沿って受け入れ率が低下します。自己回帰ドラフト機能は安定していますが、ドラフトが長くなるにつれて遅延が増加します。同氏は、DSpark に追加された 2 つのコンポーネント、信頼性判定ヘッドと負荷認識スケジューラについて具体的に言及し、「すべての投機的デコーディングと同様、ロスレスである」という重要な境界線を追加しました。
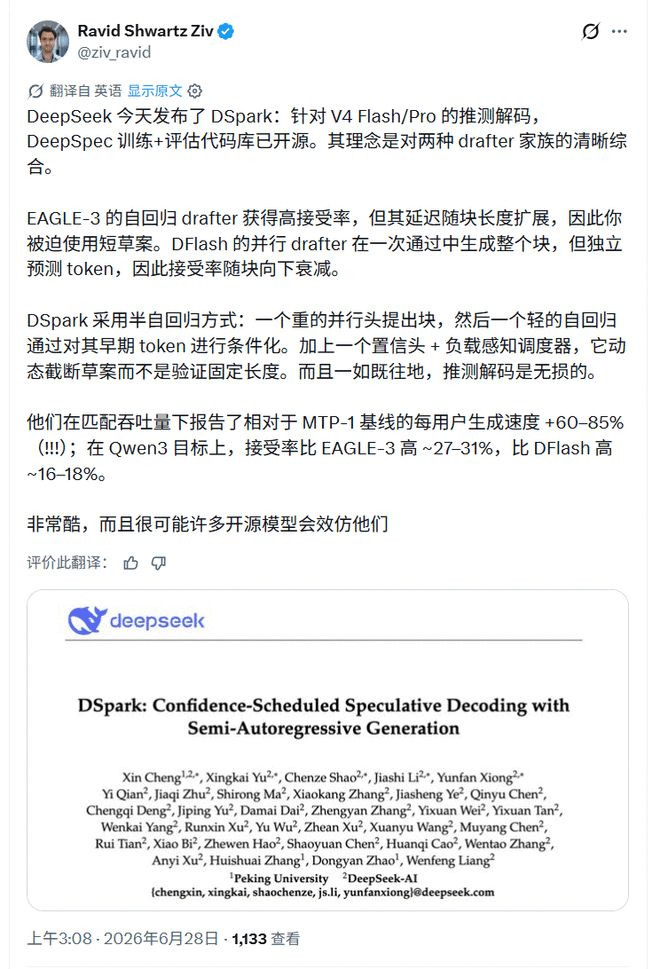
エンジニアはそれが実行できるかどうかのほうを心配しています。 vLLM の寄稿者である Rafael Caricio 氏は、デュアル DGX Spark GB10 で DeepSeek-V4-Flash の DSpark モードを実行したところ、シングルストリームのデコード速度は約 60 tok/s で、これは MTP-1 の約 1.5 倍であったと述べました。
同氏はまた、実際のコード セッションでは、合成ベンチマークでは認識できなかった問題が明らかになったと述べました。ボトルネックはコンピューティング コアの速度だけではなく、長いコンテキストの下ではドラフトの受け入れ率が大幅に低下することです。
Tech2Wild も同様の方向でオンサイト データを提供し、V4-Flash-DSpark が特定の vLLM 環境で試験的に実行されたことを示しました。ただし、そのような結果は、ハードウェア モデル、フレームワーク パッチのバージョン、コンテキストの長さ、同時実行設定に大きく依存します。別の環境では結果がまったく異なる場合があります。
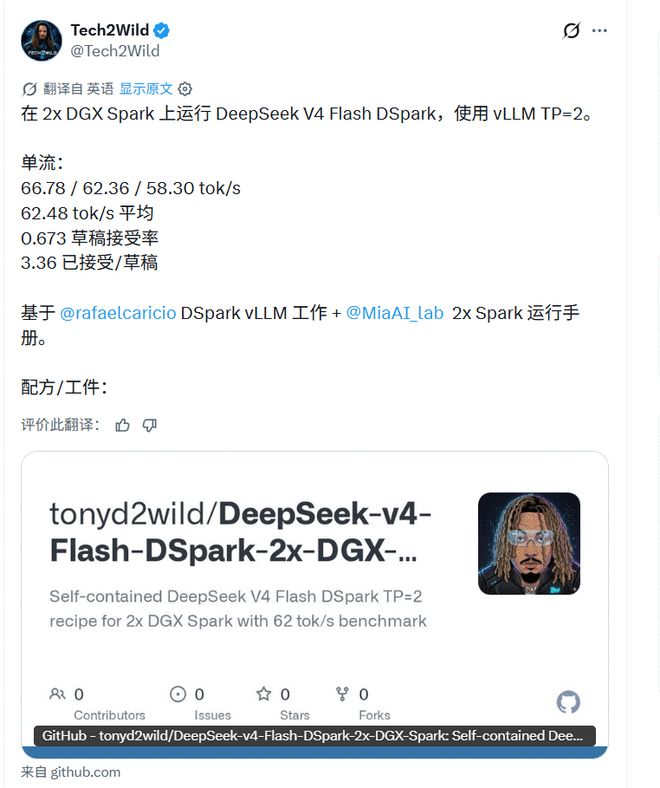
境界について具体的に思い出させてくれる人もいます。 AcingAI が指摘した
このことから、DSpark の利点の一部は負荷を認識したスケジューリングからもたらされ、スケジューリングの効果は当然、実稼働環境のトラフィック規模とハードウェア構成に依存することがわかります。
同じパワーでもより少ないコンピューティングパワー
South China Morning Post は 6 月 28 日のレポートで、推論のボトルネック、チップの圧力、ユーザーの待ち時間の観点から DSpark を調査しました。 「DeepSeekがまたどんなモデルをリリースしたのか?」という視点よりも、この視点のほうが製品の現実に近い。
AI 企業は今後もモデルの機能を比較し続けるでしょうが、機能の差が縮まれば、同じ機能をより速く、より安価に提供できる企業も競争に加わることになります。
DeepSeek のような企業は特にこれを明確にする必要があります。 DeepSeek は、低コストと高効率を外部の世界が理解するための重要な入り口として常に考えてきました。モデルのトレーニングの説明から API の価格に至るまで、最も注目を集めているのは、パラメーターのスケールが大きいかどうかではなく、同じ機能をより安価にできるかどうかです。
DSpark もこの方針を継続しています。これは、V4 が突然賢くなったことを証明するものではなく、V4 がユーザーにサービスを提供する際の推論計算能力の浪費を少なくできることを証明するものです。
もう少し視野を広げると、推論の最適化はオープンソース モデルのエコロジーにも影響を与えるでしょう。オープンソース モデルは以前は「安い」と考えられていましたが、実際に導入すると、グラフィックス メモリ、スループット、同時実行性、レイテンシ、運用保守の複雑さがすべてコストになります。
モデルをオープンソースにできるとしても、それは誰もがそれを入手できることを意味するだけです。多数のユーザーに安価にサービスを提供できるかどうかは、推論スタックが追いつくことができるかどうかによって決まります。
DeepSpec は Qwen3、Gemma、その他のチェックポイントをリリースし、この問題が DeepSeek-V4 自体にとどまらないことを示しています。移行の範囲は、コミュニティの適応、フレームワークのサポート、およびハードウェアの互換性の実際の進捗状況によって異なります。しかし、現在の公開情報から判断すると、DeepSeek は独自のモデルからこのルートを採用しています。
DSparkの価値はここにあります。単なる新しい機能ラベルではなく、本番システムに近い推論サービス ツールのレイヤーを V4 に追加します。
次に注目すべきは、DeepSeek がどれくらいの速度で実行できるかだけでなく、このルートを何人の人が通過できるかということです。 DeepSpec はチェックポイントとトレーニング プロセスをリリースしており、コスト削減のためにデコードが企業のエンジニアリング選択からオープンソース推論の一般的な手段に変わりつつあると推測されています。これは、他のフレームワークやハードウェアが対応できることを前提としています。