Anthropic は、その「フラッグシップ機能」の一部を無料ユーザー向けのデフォルト モデルに詰め込みます。北京時間7月1日早朝、クロード・ソネット5が正式に発表された。独立してタスクを計画し、ブラウザーや端末を呼び出し、コードを記述し、エラーをチェックし、複雑なワークフローを実行できます... Anthropic の公式の言葉を借りれば、これは現時点で「最もエージェントらしい」Sonnet モデルです。すでにOpus 4.8に近い性能ですが、価格は一段下がりました。
確かに美味しそうですね。
リリース期間中、Sonnet 5 の入力および出力トークン価格 (100 万あたり) はそれぞれわずか 2 米ドルと 10 米ドルです。 8月末に正常に戻ったとしても、入力トークン価格と出力トークン価格はそれぞれ3米ドルと15米ドルになります。 Opus 4.8 の標準価格 (インプット 5 ドル / アウトプット 25 ドル) と比較すると、Sonnet 5 は 40% の直接割引に相当し、初期発売期間中はさらに 40% 割引になります。
しかし、ベンチマークと価格競争だけに注目していると、Anthropic の野望を過小評価することになります。
これはむしろ、このシリコンバレーのユニコーン企業が IPO 前夜に実施した極度のストレステストに似ています。フラッグシップレベルに近いモデルが日常の生産性ツールとして使用できるほど安価であるとしても、企業顧客は依然としてそれを「パイロットプロジェクト」に閉じ込めるでしょうか? AI をコア ビジネス プロセスに真に統合する勇気があるでしょうか?
この答えによって、『ソネット 5』がどれだけ人気で売れるかが決まるだけでなく、数兆ドルの評価額を示すアンスロピックの壮大なストーリーが資本市場で実際の資金を調達できるかどうかも決まる。
同時に、Anthropic は公式文書を通じて、米国商務省が Claude Fable 5 と Mythos 5 の輸出規制を解除し、明日 2 つのモデルへのアクセスが回復されることを発表しました。

01支払い障壁から公開ベンチマークまでの 4 か月: インテリジェントなエージェントはもはや高貴ではない
これまでに最上位のOpusを使用したことがない場合は、今回Sonnet 5がもたらす影響を理解できないかもしれません。
時間を今年の2月に戻します。当時、AI にチャット ボックスの質問に答えるだけでなく、ブラウザを操作したり、ターミナルを開いたり、複雑な複数ステップのワークフローを自ら実行したりしたい場合は、おそらくお金を出して最も高価なモデルを購入する必要がありました。
それは企業予算によって支えられている少数者の特権であり、一般のユーザーは関与できないものです。
Claude を開くと、無料のデフォルト モデルにはすでにこの機能が備わっています。
AI 製品の専門家である Aakash Gupta 氏は、自身の経験を踏まえて一連の衝撃的な比較を共有しました。同氏はデータを取り出し、エージェントコーディングの本格的なテストであるSWEベンチProでは、Sonnet 5のスコアが63.2%だったのに対し、フラッグシップのOpus 4.8のスコアは69.2%で、フラッグシップレベルの90%以上に追いついたと述べた。
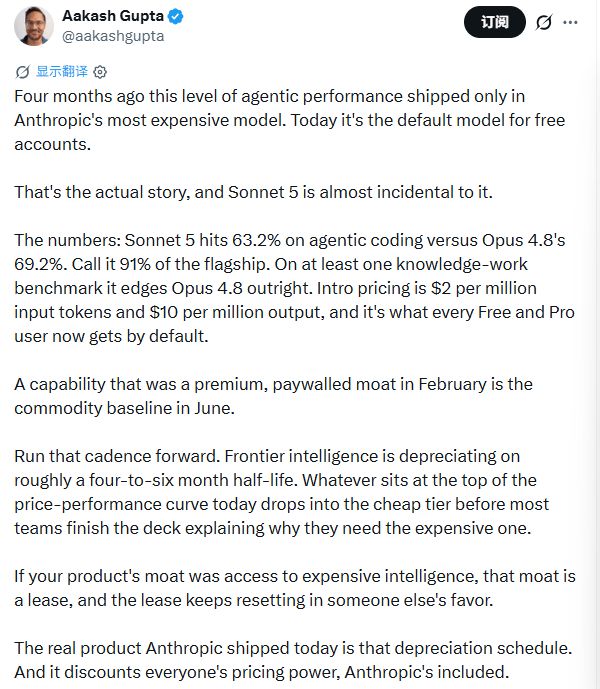
別のナレッジ ワーク ベンチマーク GDPval-AA v2 では、Sonnet 5 は 1618 ポイントを獲得し、Opus 4.8 の 1615 ポイントを直接上回りました。彼の感情は非常に直接的です。わずか 4 か月前まではハイエンドのペイウォールだったものが、今では誰にとっても標準になっています。
グプタ氏はまた、価格性能曲線上で現在どのような優位性を持っているとしても、その堀は本質的には常にリセットされる短期のリースにすぎないことを皆さんに思い出させます。Anthropic が今日実際に発表したのは、この大幅に短縮された減価償却スケジュールかもしれません。最先端のインテリジェンスの減価償却サイクルはわずか約 4 ~ 6 か月で、ほとんどのチームが高価なバージョンが必要な理由を説明するプレゼンテーションを終える前に、すでに安価な層に落ちてしまいます。
別の X ユーザー @Shawnife もソーシャル メディアで同様の感情を表明しました。
彼は、Sonnet 5 のようなリリースが過小評価されやすいと感じています。その理由は、改善が重要ではないからではなく、AI の進歩が頻繁に感じられるようになり、パワーの飛躍が正常であるように思え始めているためです。彼にとって目立っているのは、ソネットが良くなったということだけではない。むしろ、「日常的なモデル」と「最先端の機能」の間の境界線はどんどん薄くなっています。

数か月前、このレベルの推論、ツールの使用法、自律性、信頼性を達成するには、多くの場合、当時入手可能な最大のモデルを選択し、それに伴う高額なコストを受け入れる必要がありました。 Sonnet 5 は、価格帯を維持しながら Opus レベルの機能に大幅に近づいており、より幅広い使用が可能になります。
@Shawnife は次のように結論付けました。人々が「どのモデルが最も賢いのか」を問うのをやめ、「このレベルの電力が毎日使用できるほど安価になったら何を構築できるか」を問い始める段階に入っているように感じます。多くの場合、そこから本当の変革が始まります。
02 「賢くなる」だけではなく「仕事をやり遂げる」ことを学ぶ
一般のユーザーにとって、モデルがよりスマートになったという感覚は漠然としたものであることが多いですが、開発者は非常に鋭い嗅覚を持っています。
今回の Sonnet 5 のアップグレードの最大の特徴は、チャットが良くなったということではなく、非常に「信頼性」が高くなって、以前なら中途半端に行き詰まってしまうような汚い作業の処理が特に得意になったことです。
この「壊れない」品質は、企業が実験的なプロジェクトを実稼働展開に果敢に変えるための鍵となります。AI をパイロットから生産ラインに移行する際の最大の障害は、特定の素晴らしいスキルの個人スコアでは決してなく、混沌とした予測不可能な実際のワークフローの中で安定性を維持できるかどうかです。 80 段の道の 64 段目に到達した後で道に迷ったガイドは、正直な地図ほど役に立ちません。
まずは客観的なデータを見てみましょう。
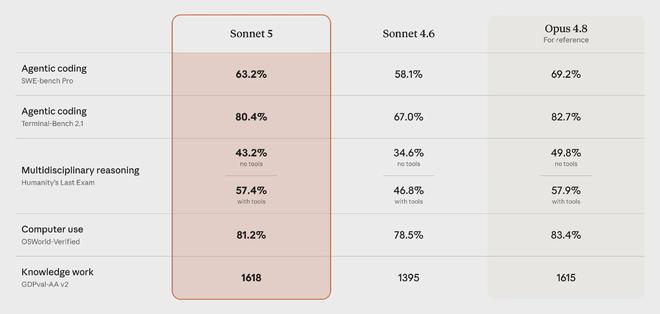
プロキシ コーディング テスト SWE-bench Pro では、Sonnet 5 は 63.2% を獲得し、前世代の Sonnet 4.6 は 58.1% を獲得しました。この上昇により、ソネット 5 は作品 4.8 の 69.2% に近づきました。
実戦をより重視した別のコーディング評価である Terminal-Bench 2.1 では、その差はさらに縮まり、Sonnet 5 は 80.4% に達し、Opus 4.8 は 82.7% に達し、ほぼ同点となりました。
最終的な人間テストをベンチマークとして使用した多分野の推論に関して、Sonnet 5 はツールの助けを借りて 57.4% のスコアを獲得しました。これは、Opus 4.8 の 57.9% と基本的に同じです。
実際のコンピュータ操作をシミュレートする OSWorld-Verified の評価では、Sonnet 5 のスコアは 81.2% で、前世代の 78.5% に比べて大幅に向上しました。
これらの数字は、Sonnet 5 が前世代のパッチワークではなく、フラッグシップ モデルと非常に重複するパフォーマンス範囲に直接飛び込んでいるという事実を総合的に示しています。
主観的な経験を見てみましょう。
AI コード エディター Cursor の共同創設者である Sualeh Asif 氏は、これを日常業務の実行に使用しました。その結果、この新しいモデルは確立された計画に忠実であり、開発仕様に従い、最終的には安定した出力を備えた真に信頼できるエンジニアのように、一連のマルチステップの明確なコード変更を快適なコストで実現できることがわかりました。
自動化プラットフォーム Zapier のシニア エンジニアであるダニエル シェパード氏は、同社の複雑な Salesforce アカウント階層を自動的に更新し、厳密にフォーマットされたリリース通知を送信するという、以前のモデルでは実行できなかったタスクをそれに与えました。以前のモデルは途中で止まってしまうことが多かったのですが、しかし、Sonnet 5 はワークフロー全体を最初から最後まで完了します。プロセス全体を確実に完了できるこの機能は、自動化の経済性を完全に変えます。
ポッドキャスト ホストのベン デイビスの経験は、別のレベルの感情を引き出します。彼の最初の反応は、このベンチマーク テストのパフォーマンスが実際には非常に低く、特に推論の点で非効率的であるということでした。決して速いモデルではありませんでした。価格が下がったとはいえ、非効率の問題もあり、決して安いモデルではありませんでした。

しかし話題が変わると、第一印象は「他の人はみんな間違っていると感じた」と語った。これはとても良いモデルでした。彼が使った表現は、Sonnet5 が「次世代」の匂いがするというものでした。
同氏は、Fable は誰もが手にした最初の「次世代」モデルであると説明しました。このモデルの特徴は、ハイスコアではありませんが、途方もなく長い時間連続実行する能力、サブエージェントをうまく処理する能力、自身の動作をチェックする能力、そしてプロンプトのギャップを埋め、以前のどのモデルよりも言葉の意味を真に理解する能力です。
Sonnet 5 は最初のテストからこのフレーバーを継承し、明示的に要求されずに独自の出力をチェックし、積極的にエラーをチェックしました。ただし、ほとんどのクロード モデルと同様に、時々説教しすぎたり、聞かれていない質問に答えたり、簡単に本題から逸れてしまうことも認めました。幸いなことに、それを指摘すると、あまり長い間言い争うことはなく、ただ間違いを認めて元の軌道に戻ってくれます。
そこで彼の結論は、Fableが本当に戻ってくるまでは、これが最高のモデルになるかもしれません。
最後に、実際のビジネス実務を見てみましょう。 Box CEO の Aaron Levie 氏のテスト結果は、こうしたこれまでの感情を裏付ける確かな証拠を提供しています。

Box は自社開発した AI 複雑な作業評価システムを内部に備えており、特にモデルが実際の企業ドキュメントを端から端まで読み込むことができます。彼はソネット 5 を投げ込んで転がり、結果は非常に素晴らしかったです。エネルギー産業など、収益性の高い複雑性の高いいくつかのセクターでは、Sonnet 5 が前世代より 4.7 パーセント ポイント、小売業で 4.4 パーセント ポイント、プロフェッショナル サービスで 2.6 パーセント ポイントリードしています。
Levi 氏はまた、いくつかの具体的な実践例についても共有しました。資金調達に関するデューデリジェンスを行う際、ソネット 5 は元の貸借対照表から会社の流動性とレバレッジ比率を計算し、情報源報告書で過小評価されている負債資本比率さえも見つけ出し、文書自体で認められたものだけでなく、3 つのローンすべてを違反としてマークしました。
オーバーホールコストを分析する際、他のモデルはテーブル内のすべての数値を無意識に合計してしまう可能性がありますが、それを会社独自に定義した KPI フレームワークに巧みに制限し、個別に追跡する必要がある生産損失コストをきれいに取り除き、スプレッドシート内の破損した参照セルを見つけるための手がかりも追跡します。
SKU の収益分析を行う場合、合計で割るというよくある落とし穴には陥りません。代わりに、正しいサブカテゴリの分母に対する各製品の寄与度を正確に計算し、特定の製品カテゴリがランキングのトップ 9 に入らなかった理由を説明することもできます。
Levy 氏は、非構造化データが非常に複雑な領域において、Sonnet 5 が本番環境の旗印を担う能力を確かに実証していると感じています。同氏は、このモデルが間もなく顧客に Box AI Studio で提供され、同社独自のパーソナライズされたインテリジェンスを構築できるようになる予定であることを認めました。
03 トークナイザーの台帳: 安くなりますが、必ずしもお金を節約できるわけではありません
法人顧客にとって、複雑な文書を安定して処理できることこそが、喜んでお金を払う理由なのです。しかし、喜んで支払うための前提条件は、請求額が予算内に収まっていなければならないということです。
表面的には、Sonnet 5 の価格は大幅に下がったようで、わずか 2 ドルと 10 ドルの特別価格で Opus に近いスマートフォンが購入できます。しかし、テストが終わると多くの人が振り返り、全員に「落とし穴を避ける」ように注意を促しました。
AIの詳細を専門とする研究者サイモン・ウィリソン氏にはある習慣がある。新しいモデルがリリースされるたびに、彼は開発者ドキュメントの「新機能」セクションに直接アクセスします。通常、そこには公式発表よりも実用的な情報が隠されているからです。今回、彼は慎重に検討する必要がある技術的な詳細を本当に掘り出しました。
Sonnet 5 には単語セグメンターの新しいバージョンがあり、テキストの処理方法が変更されました。この直接的な結果として、同じ入力テキストの場合、現在のトークン消費量は古いモデル Sonnet 4.6 よりも 30% 近く多くなります。

彼は公開されているクロード トークン カウント ツールを使用して実際の測定を行いましたが、その結果は非常に直感的でした。彼はテストに世界人権宣言の英語版の全文を使用しました。古いモデル Sonnet 4.6 では、2,356 トークンのみが消費されました。 Sonnet 5 では、直接的には 3,341 トークンに拡大し、1.42 倍に増加しました。スペイン語版に切り替えると、トークンの数は 3572 から 4747 に増加し、1.33 倍に増加しました。
最も残酷だったのは、4,000 行を超える Python コード ファイルをテストすることでした。トークンは44014から56113に1.27倍に急増しました。彼を安心させてくれたのは簡体字中国語だけだった。 2 つのモデルの中国語テキストのトークン消費量は基本的に同じで、わずか 1.01 倍の変動のみで、ほとんど無視できるほどでした。
この発見は、英語の処理に大きく依存している開発者や、大量の Python コードを実行している開発者にとって、モデルのタスクあたりのコストが宣伝されているほど良くない可能性があることを意味します。
実際、Anthropic は公式文書の脚注でこれを認めています。彼らは、優遇価格を設定する目的は、移行期間をほぼコスト中立に保つことであると説明した。言い換えれば、数ドルの価格引き下げ余地の一部は、トークンのインフレを防ぐために使用されます。
この隠れた変数のせいで、最初は値下げを称賛していた一部の開発者はすぐに落ち着き、通常のワークロードに基づいて計算を再計算し始めました。
04 ソーシャルネットワーク上では大喧嘩になり、「臭い」と叫ぶ人もいれば、返金を求める人もいた。
モデルがリリースされるたびに、ソーシャル メディア上の声は 1 つだけではありません。 Sonnet 5 が稼働してから最初の数時間で、X プラットフォームに対するフィードバックはすぐに分かれました。
この更新が誠実であると感じる人もいれば、無礼に失望を表明する人もいます。
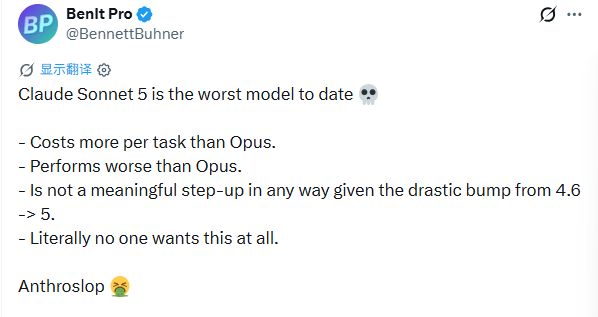
X ユーザー @BennettBuhner の苦情は非常に的を射ていました。彼は、ソネット 5 がこれまでで最悪のモデルであると直接言いました。その理由は、各タスクの実際の消費コストは Opus を使用するよりも高いものの、パフォーマンスは Opus よりも悪く、4.6 という大きなバージョン番号から 5 への飛躍はどの面においても意味のある改善ではないためです。彼は明らかに皮肉を込めて「アンスロスロップ」という造語を使って不満をぶちまけた。
X ユーザーの @weswinder も同様の混乱を表明しました。彼の論理は単純だ。 Sonnet 5 は Opus 4.8 よりも高価に見えますが、それほどスマートではありません。より悪い結果を得るためにより多くのトークンが必要な場合、いわゆるトークンあたりの単価の利点は実際には無意味になります。彼は、このモデルの重要性は何ですか?と直接尋ねました。
別の X ユーザーである @DaveShapi は、ジェットコースターのような体験をしました。彼の最初の反応はショックだった。彼自身の言葉では、自分がこんなことを言っているとは信じられませんでしたが、ソネット 5 の最大努力モードはあまりにもきつかったです。彼はそれを、リスの入った箱に大量のコカインを与え、「神のご加護を」と言いながら、向こうから何が出るのを待っているような気分だと表現した。
次に彼は、ソネット 5 はあまりにも簡単に主題から逸れ、ほとんどのクロードと同じように説教臭く、尋ねてもいない質問に答えるだろうし、全体的に傲慢すぎると不満を述べました。幸いなことに、利点があります。あなたがその間違いを指摘しても、それはあまり長い時間議論しません。ただ自分の間違いを認め、何が間違っていたのかを尋ねます。心配する必要はありません。彼は力なく尋ねました、なぜこれにお金をかけなければならないのですか?
しかし、不満の声とは別に、全く異なる判断を下す人もいた。 X ユーザー @kimmonismus のコメントにより、より戦略的なレベルの精査が行われました。
彼が得た評価結果は、確かにソネット 5 は誰もが予想したであろう前世代よりも優れているが、すべての評価においてオーパス 4.8 よりも弱いというものでした。彼が特に理解していないのは、パフォーマンスに飛躍がないのに、なぜバージョン番号が 4.8 などの番号ではなく 4.6 から 5 に直接変わるのかということです。通常、バージョン番号の大きな飛躍は機能の大幅な飛躍を意味しますが、今回は明らかにそうではありません。
@kimmonismus さんは、このリリースは全体的に混乱を招き、答えよりも多くの疑問が生じたと述べました。彼は、Fable 5 の文脈で Sonnet 5 を検討せずにはいられませんでした。Fable 5 の中に非常に強力なパフォーマンスを備えた Fable 5 が存在することは誰もがすでに知っており、さらに優れた Opus が内部にあると想定できることも知っていたのに、なぜ彼らは長い間保留し、良くも悪くもなかった Sonnet 5 だけをリリースしたのでしょうか。
同氏は、これはおそらく現在の自制の必要性によるものではないかと推測した。本当のハイライトは、規制に関するコミュニケーションが全体的に依然として遅れているため、Anthropic が会話に参加し、それを忘れないようにするために、ポジティブな声を維持することも含めて、今何かをリリースする必要があるということです。彼の意見では、ソネット 5 のリリースはおそらくこの文脈でのみ理解でき、ある種の過渡期のような後味が残り、少なくとも個人的には一般的に残念なものです。
これらの批判に直面して、多くの人が人類学を支持する声をあげました。
Sonnet と Opus を比較すること自体が、Sonnet が市場を飛び越えたことを示すと考える人もいます。ミッドレンジ製品はフラッグシップモデルと比較されていますが、これはまさにパフォーマンスが第一段階に詰め込まれていることを証明しています。また、無料ユーザーはこのレベルのモデルを無料で購入できるようになったため、文句を言う必要はないと指摘する人もいます。
この種の論争自体が、ソネット 5 が微妙なバランス点の上を歩いていることを示しています。驚くべきものにはまだ程遠いですが、失敗には程遠いです。本当の試金石は、リリース当日の口コミではなく、今後数週間で実際に毎日のワークフローをこのモデルに移行する開発者が何人いるか、そして移行した開発者が月末に請求書を受け取ったときにうなずくか眉をひそめるかだ。
05IPO前夜の「封印」と抑制の危険性
Anthropic は、評価額 1 兆ドルに向けて猛スピードで突き進んでいるスター企業として、セキュリティを非常に厳重にしています。今回、Sonnet 5 のシステム カードでは、セキュリティ評価が大きなスペースを占め、多くの詳細が明らかになりました。
まずは進歩している分野について話しましょう。前世代の Sonnet 4.6 と比較して、Sonnet 5 はさまざまな面で実質的な改善が施されています。
幻覚や卑劣な行動の発生率が低く、悪意のあるリクエストの拒否に優れ、エージェント シナリオでのヒント インジェクション攻撃に対する耐性が高くなります。同当局者は一連の自動化された行動監査を実施しており、検査の範囲は協力、虐待、欺瞞などの一連の不適切な行動を対象としている。 Sonnet 5 の全体的な不適切行為スコアは前世代よりも低く、より安全であることを意味します。
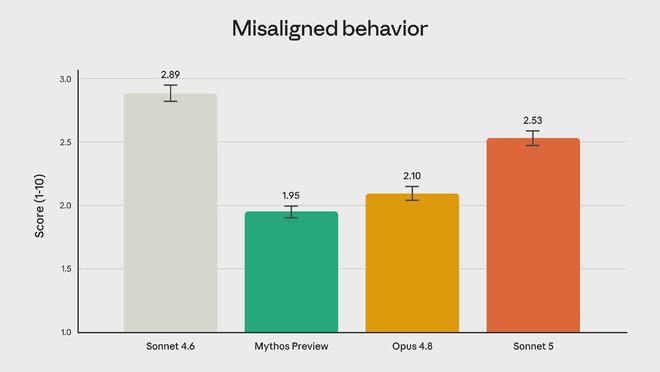
しかし、正直に言うと、それは最も安全な方法ではありません。システム カードには、より高機能な Opus 4.8 や、特にネットワーク セキュリティに焦点を当てた Claude Mythos Preview と比較して、Sonnet 5 は同じ評価で不正行為の割合がわずかに高いことが示されていると明確に記載されています。この記述は非常に慎重ですが、問題を説明するには十分です。実際、より強力なモデルは、いくつかのセキュリティ面で優れたパフォーマンスを発揮します。
最も直感的な比較は、Mozilla と共同で開発されたエクスプロイト テストから得られます。
このモデルのタスクは、Firefox 147 ブラウザーで使用可能なソフトウェア エクスプロイトを作成することでした。 Sonnet 5 の成績表は非常にきれいです。使える脆弱性は全くなく、成功率もゼロです。部分的な成功率は 13.2% で、前世代の Sonnet 4.6 の 8.8% よりわずかに高くなりますが、どちらの数字も Opus 4.8 の前に言及する価値があります。 Opus 4.8 は利用可能なエクスプロイトの 68.8% を生成し、Mythos 5 は 88.4% にも達しました。
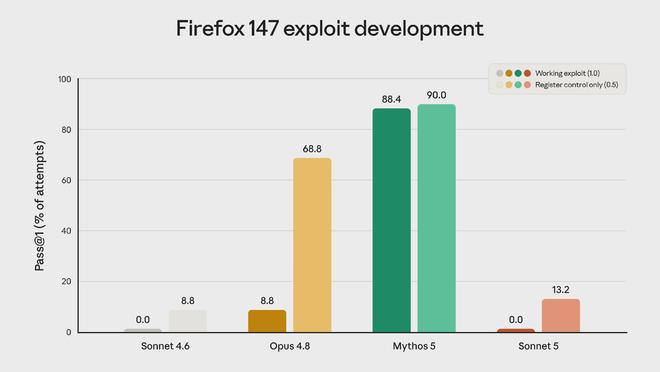
つまり、Sonnet 5 の汎用性は飛躍的に向上しましたが、非常に破壊力を必要とするネットワーク セキュリティ スキルに関しては、依然として 2 つの兄との間に差があります。
巧妙すぎて混乱が生じるのを防ぐために、Anthropic のアプローチは、デフォルトでネットワーク セキュリティ保護を直接有効にすることです。このシステムは、危険なネットワーク使用行為をリアルタイムで検出し、ブロックできます。モデルが危険な領域に触れようとすると、保護シールドがポップアップします。
当局者は、この一連の保護措置の厳格さはオーパス4.7および4.8と同じであると説明した。 Sonnet 5 の全体的なネットワークセキュリティリスクレベルは低いと判断したため、Fable 5 を制限するようなより厳しい措置は講じませんでした。
サイバーセキュリティ研究に対する保護をそれほど必要としない特別なニーズを持つ組織のために、Anthropic は「サイバー検証プログラム」チャネルを提供しています。すでにプログラムに参加している組織は、Sonnet5 上で同じアクセス権を自動的に受け取るため、再申請する必要はありません。一般に、ネットワーク セキュリティの仕事に真剣に取り組んでいる人は Opus4.8 を使用することが公式に推奨されています。
06 Sonnet 5 は IPO の物語の中でどのような役割を果たしますか?
アンスロピックは上場を急いでおり、その評価額は1兆ドル近くにまで上昇している。このノードに Sonnet 5 をプッシュすることは、単なる日常的なアップデートというよりは戦略的な動きに似ています。
過去6か月の資金調達の軌跡を見ると、実に速いスピードで進んでいます。今年2月、アンスロピックは評価額3,800億ドルで300億ドルの資金調達を完了した。当時の年間収益は 140 億米ドルに達し、過去 3 年間で毎年 10 倍以上に成長しました。 5月下旬までにさらに650億ドルのシリーズH資金調達を完了し、評価額は一気に9,650億ドルに跳ね上がり、年間収益は470億ドル以上に急増した。
しかし、この成長率は避けられない精査ももたらします。アナリスト会社D.A.のテクノロジーリサーチディレクター、ギル・ルリア氏はこう語る。 Davidson 氏はそれに冷や水を浴びせ、最先端のモデルという点では Anthropic が先を行っているように見えるが、しかし、現在の使用法のほとんどは試験や実験によるものであり、持続可能ではない可能性があります。開発者の好奇心旺盛なトライアルを、長期契約を伴う運用レベルの依存関係に変えることは、AI 研究所が直面する最も重大な障害です。
この文脈で Sonnet 5 の価格戦略を見ると、その論理が明らかになります。高価な Opus クラスのモデルを試している企業顧客は、Sonnet 5 が財務部門が大規模に承認する価格帯で十分な製品品質を提供していることに気づくかもしれません。これが実現すれば、業界の実験から展開への移行が加速する可能性があり、これはAnthropicにとって自社の評価を正当化するための重要なステップとなる。
無視されがちな兆候がもう 1 つあります。ソネット 5 の発売のちょうど 1 日前、カリフォルニア州知事ギャビン ニューサムは、無料の従業員トレーニングとともに、すべての州政府機関にクロードを 50% 割引で提供するパートナーシップを発表しました。これは、Anthropic が継続的な経常収益を受け取ることを意味します。
アンスロピックのアメリカ大陸責任者であるケイト・ジェンセン氏は、これはカリフォルニアを運営し続ける人々のためにクロードを利用できるようにするためだと語った。この協定はカリフォルニア州のさまざまな都市や郡にも拡大されました。これは一度限りの販売ではなく、収入基盤が開発者コミュニティに浸透し、公共サービス システムに浸透することを可能にする一種の深い結びつきを表します。法人顧客にとって、複雑な文書を安定して処理できることこそが、喜んでお金を払う理由なのです。
07競争環境と評価圧力
Sonnet 5 のリリースのタイミングは、業界全体で最も競争が激しい時期でもあります。
OpenAIは3月に評価額8,520億ドルで1,220億ドルの資金調達を完了し、自社のIPOの準備も進めている。イーロン・マスク氏のスペースXとxAIの合併後のIPO価格は1株当たり135ドル、評価額は1兆7700億ドルとなった。 Google、Meta、そして資金豊富なアジアの多数の AI スタートアップ企業はすべて、同じエンタープライズ市場を目指して争っている。
これは金を燃やす軍拡競争であり、誰も立ち止まって息をしようとはしません。
PitchBook アナリストの Harrison Rolfes は、これについて非常に現実的なことを言いました。彼が言いたいのは、評価額や収益などの表面的な数字だけを見ないでください、ということです。それらはすべてお金を燃やすことで積み重なることができます。本当に重要な数値は粗利益率であり、これは企業が稼ぐ 1 ドルごとにコンピューティング能力や電気料金などの直接コストを差し引いた後に残る金額です。この数字は今まで外の世界では見たことがありません。粗利率が悪ければ、いくら売上が高くても赤字でしか儲からないのです。
したがって、2026年のAI企業のこの波の上場は、インターネットバブル以来最も成功した資本の饗宴となるか、あるいは公開市場の投資家にとって、本を見ずに話を聞くだけでいかに高くつくかを思い知らされるマイナスの教材となるかのどちらかになるだろう。
この文の意味は、ウォール街が収益の急速な成長に簡単には感銘を受けないだろう、ということだ。彼らは財務報告書を層ごとに剥がして、1 ドルの収益の裏でどれだけのコンピューティング パワーが消費されているかを確認します。売上総利益率は、AI 企業が技術的な奇跡であるか資本のブラックホールであるかをテストする重要な指標です。公設市場は残酷だ。
結論
ボールはもうアウトです。Sonnet 5 の本当のテストは、リリース当日のベンチマーク チャートではなく、翌月の請求率と維持率で決まります。開発者は本当に日常のワークフローを移行したのでしょうか?月末に請求書を受け取ったとき、彼らはうなずきますか、それとも眉をひそめますか?重要なのはこれらだけです。
内訳すると、答えを決定する変数は 3 つあります。
1つ目はエージェントの信頼性です。ベンチマーク テストでは機能の上限をテストしますが、運用環境では長期的な安定性をテストします。何千もの開発者が独自の混沌とした予測不可能なシナリオで実行を開始した後、Sonnet 5 がチェーンから外れるかどうかは、実験室で実行されるスコアがどれだけ高いかよりも重要です。
2 つ目は、トークナイザーに隠されている bill 変数です。法人顧客がビジネスシナリオに基づいたコスト計算を行わず、宣伝されている各トークンの単価だけを見て「安い」と思っていると、割引期間が終了したときに実際の請求額が衝撃的になる可能性があります。
3 番目の変数はさらに興味深いものです。Sonnet 5 が本当に成功し、開発者が大規模に移行し、企業顧客もそれを実稼働プロセスに導入すると仮定すると、次に何が起こるでしょうか?
オーパスの立場は厄介なものになるだろう。 Sonnet がすでにほとんどのシナリオではるかに低いコストで十分なパフォーマンスを提供できる場合、誰が 2 倍以上の費用をかけて Opus を呼び出すでしょうか?そのとき、Anthropic は自身の成功によって反撃されるかもしれません。ソネットの売れ行きが良くなればなるほど、オーパスの売上が圧迫されることになり、オーパスは粗利益がより高い製品ラインとなります。
率先して価格を下げて利益率を圧縮するか、顧客が高価格の製品から低価格の製品に流れるのを見守るかのどちらかです。どちらの道もたどるのは簡単ではありません。
今回の Anthropic の賭けは、2 つのエンディングのちょうど真ん中にあります。
フラッグシップに近い性能を持ちながらも、価格を大きく展開できるモデルが登場した。同社が証明したいのは、最先端の機能は最も高価な主力レベルに留まるだけでなく、企業が毎日使用できると同時に収益を上げられるインフラストラクチャにもなり得るということです。
Anthropic が実際に公開市場に登場するとき、投資家は答えを出すだろう。この「フラッグシップに近い、価格の下落」ルートが 1 兆ドルに近いストーリーをサポートできるだろうか。